
深度学习应用开发:大作业
基于强化学习的微信小游戏
选题背景
在过去的20年里,AI在游戏中的发展历历在目,AlphaGo击败世界围棋冠军李世石,OpenAI Five击败DOTA2世界冠军,以强化学习、深度强化学习为代表的游戏AI被大量研究。为什么AI需要游戏?游戏提供了定义和构建复杂AI问题的平台,不同于传统学术界的AI问题都是单一的、纯粹的,同时,游戏还能提供海量的内容和用户数据,还可以无视现实世界的规则,同样的游戏也需要AI来提升它的乐趣和可玩性。
2018年,微信小游戏跳一跳火遍微信朋友圈,此后小游戏持续升温,即点即玩的特点让它走向数亿级用户,随着小程序生态的逐渐完善,微信小游戏也成为互联网企业的必争之地。轻便休闲一直是小游戏最大的特点,但是初期流量型产品的快速变现,大部分的小游戏显得有些粗制滥造,小游戏产品必将要开始注重游戏性、美术等,走向精品化,而且今年9月份于厦门举办的第十一季微信公开课微信小游戏开发者大会上,我们发现微信小游戏精品化的发展速度远比想象中更快。
本项目构建了一种基于DQN算法,使用Python Flask、TCP协议连接的微信小游戏强化学习。
开发环境
微信开发者工具:调试基础库 2.29.0
Python环境:
- python 3.9.0
- flask 2.2.2
- OpenCV 4.6.0
- Tensorflow 2.5.0
数据处理
这里涉及到了三个数据及基本加工方式如下:
- state(当前截图文件),文件格式,尺寸:365625,颜色空间:RGB,采样位数:24。使用 OpenCV 进行处理,将其转化为尺寸为:8484 的灰度图
- reward(当前分数),int 型,
- status(当前游戏状态) ,bool 型,
微信小游戏每过500ms就通过wx.request向 Python Flask 发送state、 reward和 status 消息。Python Flask 始终在后台监测是否有消息传来,以及是否需要发送消息,接收来自微信小游戏的数据后,存储在本地。
模型设计
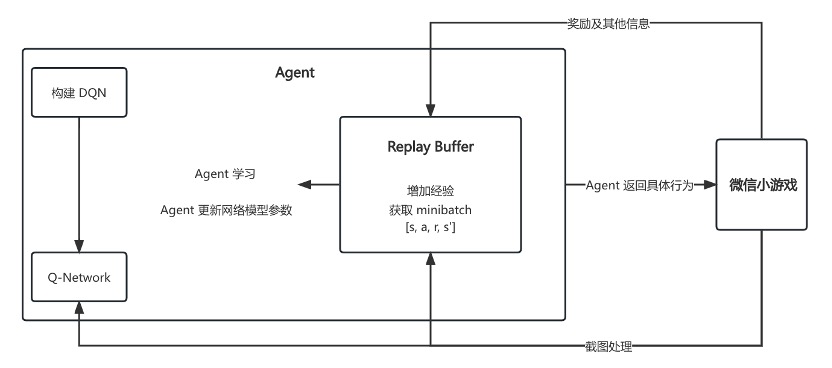
详细来说,DQN 算法中,Agent 将 Q-network 和 ReplayBuffer 放在一起,它将处理诸如更新目标网络,执行梯度下降及获取操作之类的事情。当 Agent 在环境中采取行动时,环境会给予 Agent 一些反馈,包括有关执行后的游戏状态、该操作产生的奖励以及游戏是否完成的信息。这些反馈将存储在 ReplayBuffer 中。具体而言,ReplayBuffer 将存储状态、操 作、奖励和新状态的转换。 Agent 将通过仅保存一次状态,从缓冲区采样时再将其 拆分为状态和新状态,从而使内存效率更高。当 Agent 更新 Q-network 时,Agent 将从此 ReplayBuffer 进行采样。
以下是算法中使用到的关键函数:
- frame_processor()处理 DQN 的输入
- build_q_network()构建 Keras 模型
- GameWrapper 将成为游戏环境的包装器。它管理提供给 DQN 的状态。
- ReplayBuffer 将负责管理存储的经验,并根据需要从中抽样。
它们之间的关系如下图所示。build_q_network()会创建一个神经网络微信小游戏。微信小游戏将截图先传入 frame_processor(), 经过处理后交给 agent 放入神经网络和 ReplayBuffer 中。与此同时将 reward 等信息传到 agent 中,agent 将信息存储在 ReplayBuffer 中,而后从 ReplayBuffer 提取数据进行训练等。
DQN算法
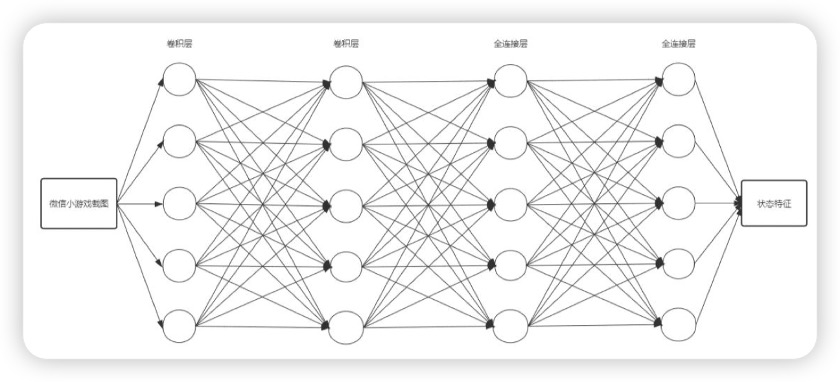
DQN 利用深度卷积神经网络逼近值函数。本文神经网络采用两层卷积层,两层全连接层。在微信小游戏中,看到的是 375625 的 RGB 图像。然而对于 AI 来说,每一帧在 3756253 = 703,125 像素上操作对计算要求很高。为了解决这个问题,本文预处理框架以减小其尺寸,将传 入的图片,即 state,先利用 OpenCv 处理为 8484 的灰度图,而后放入神经网络中 提取特征值。
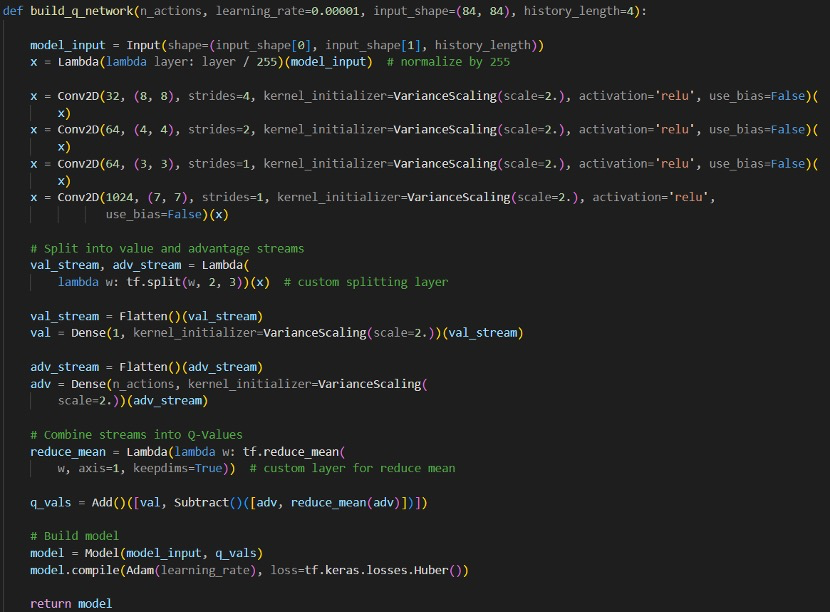
对于其中的卷积层及全连接层参数如下(history_length=4):
- 2d卷积:filters=32, kernel_size=8, strides=4, activation= ‘relu’, use_bias=False
- 2d卷积:filters=64, kernel_size=4, strides=2, activation= ‘relu’, use_bias=False
- 2d卷积:filters=64, kernel_size=3, strides=1, activation= ‘relu’, use_bias=False
- 2d卷积:filters=1024, kernel_size=7, strides=1, activation= ‘relu’, use_bias=False
将结果结果分为价值流与优势流后,展平后再分别进行全连接层:
- 价值流全连接层:512 -> 1
- 优势流全连接层:512 -> 4
那么这里的价值流结果就对应 restart,优势流结果就对应 action
模型训练
参数设置
- ENV_NAME: agent学习的Gym环境名设置
- SAVE_PATH: 训练到一定程度的agent进行保存的路径
- TENSORBOARD_DIR: tensorboard的存放路径
- USE_PER: 启用优先经验回放机制的flag开关
- PRIORITY_SCALE: 优先经验回放机制的采样率,0则为完全随机采样,1则为完全根据优先级进行采样
- TOTAL_FRAMES: 训练的图片帧数
- MAX_EPISODE_LENGTH: 一个训练episode中训练的图片帧数
- FRAMES_BETWEEN_EVAL: 验证的图片帧数
- EVAL_LENGTH: 一次验证episode中使用的图片帧数
- UPDATE_FREQ: 更新目标网络时选择更新的图片帧数
- DISCOUNT_FACTOR: 未来奖励折扣率
- MIN_REPLAY_BUFFER_SIZE: 在开始更新agent前replay buffer中要有的最小缓冲规模
- MEM_SIZE: replay buffer中的最大缓冲上限
- MAX_NOOP_STEPS: 在每次验证前为赋予随机性执行的随机操作的数量
- INPUT_SHAPE: 传入图片的维度,基于当前的模型架构,传入网络的图片的每个维度的度量不能低于80
- BATCH_SIZE: agent一次学习的样本数量
- LEARNING_RATE: 学习率
训练及模型调优
首先将微信小游戏中agent在某一时刻的状态观察截图传入frame_process()函数中,使用openCV中的图片处理函数cvtColor()将维度为2101603的图片经由卷积神经网络处理为84841的灰度图.
构建q-network模型
对Gym提供的训练环境进行函数封装, 并定义ReplayBuffer类
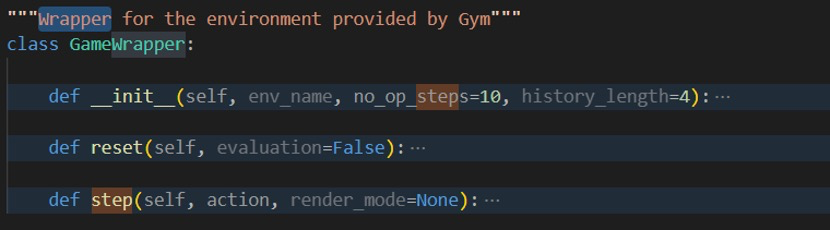
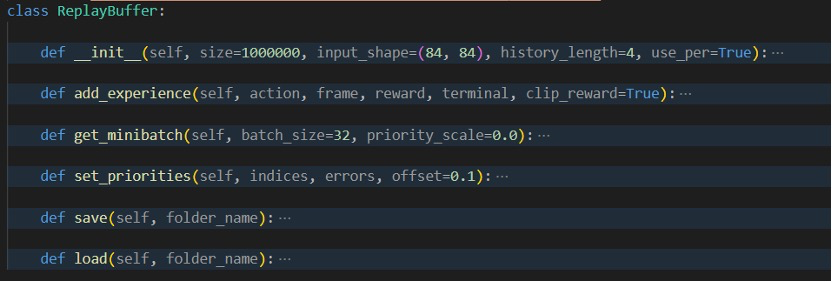
定义一个可进行训练及调整的Agent,并在其中根据传入数据动态更新q-network

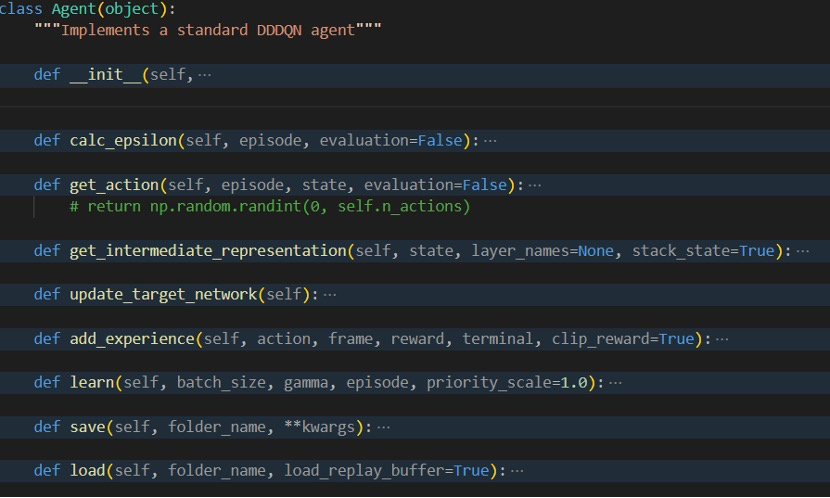
在主函数中通过定义agent、Main_DQN和Train_DQN以及ReplayBuffer进行轮次训练
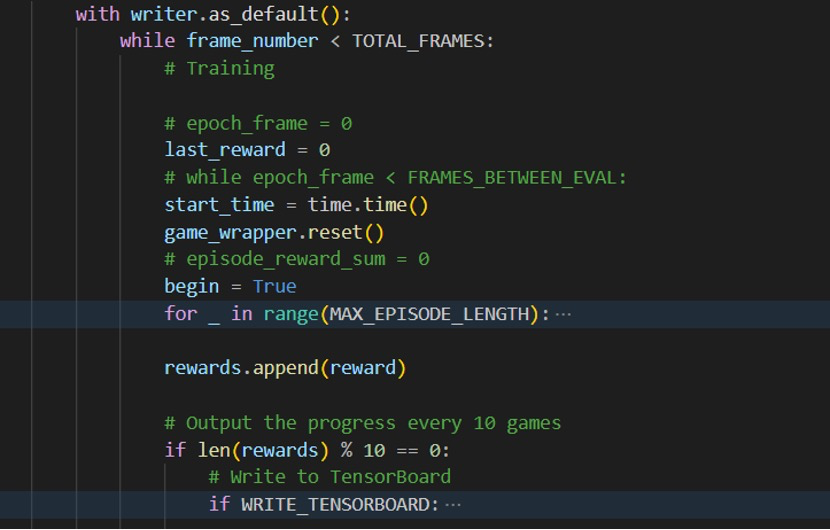
模型评测
该模型的评测方式可通过程序运行结果进行直观的呈现:
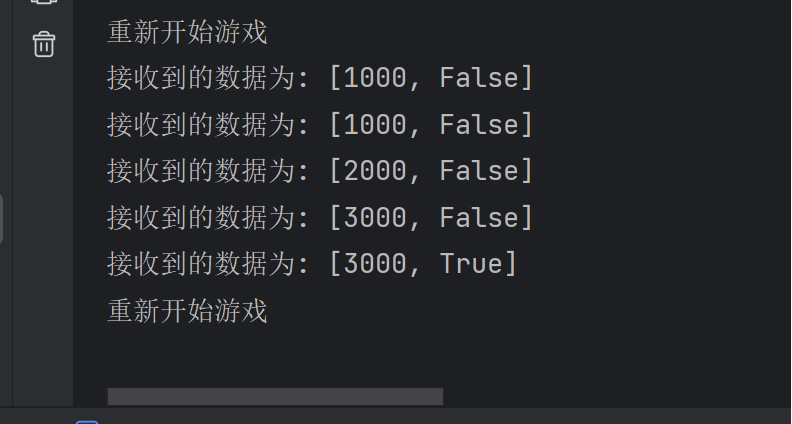
当flask平台通过TCP进行数据传输成功接收到微信小游戏的游戏数据时,将在终端显示台不间断的打印出游戏当前的得分以及状态当DQN算法成功接收到flask平台的发送数据并成功经由q-network处理以及训练时, 会在终端显示台不间断的打印出当前游戏的运行状态及得分情况, 并在一轮游戏终止即agent在游戏环境中死亡时重新开始游戏进行新一轮的训练:
项目组成员分工和贡献(分组作业适用)
组长:A、32001014,计算机2001, evinciy@qq.com, 13693905866
组员1:B、32001067、计算机2004、2577839870@qq.com、18268026747
组员2:C、32001261、计算机2004、shuhenxin@qq.com、18357901815
A:0.33,B:0.33,C: 0.34
课程感想
暂无
参考文献
[1] 周昱杉 IME:基于神经网络的游戏 AI 模仿及评价方法[D].北京大学,2021
[2] 王点 基于深度增强学习的五子棋人工智能实现[D] 四川大学,2017
[3] Mateas M Expressive AI: games and artificial intelligence[J]. DiGRA ༿—Proceedings of the 2003 DiGRA International Conference: Level Up, 2003
