
人工智能概论:大作业
基于 UWB 进行动作识别的研究
**摘要:**作为非嵌入式 UWB 技术的发展与快速的普及大大降低了室内精确定位的成本,并在可预见的将来这一趋势将持续蔓延。但与此同时,为了达到近距离动作识别的需求,一般还会在 UWB 的基础上增加其他传感器模块。为了解决单 UWB 模块功能单一性问题,本文记录了基于已有 UWB 模块的 CIR 信号分析尝试开发一套动作识别技术的前期探索过程。同时,也对项目已有进度进行了总结和展望,为未来可能的探索打下基础。
**关键词:**UWB、CIR、动作识别
目前关于动作识别(Action Recognition)相关的技术日益完善,尤其是以基于2D图像(视频)数据识别及检测的技术领域,已经可以具备低硬件成本、高识别精度、强抗干扰能力等多方面的优秀效果。但非主流的基于电磁波信号识别机检测方向上,相关技术开发相对滞后。同时,作为非侵入式的数据采集方式尽可能保证了用户数据的隐私性与安全性。因此,当社会对个人信息保护意识逐渐增强后,间接性的动作识别理应迎来一波发展。本文在 STM32 单片机基础上开发的超带宽寻迹定位模块(Ultra-wide band,UWB)模块,通过采集信道的数据并基于此进行动作识别相关的研究。
介绍
UWB 模块作为非侵入式数据采集方式典型代表,目前已经被广泛地应用在定位领域内,尤其以室内高精度定位为代表的定位技术,凭借着 UWB的高精度及强抗干扰能力已经可以将分辨率控制到厘米到分米级别。一般情况下 UWB 模块采集的数据有如下三种数据类型:
- UWB 标签与基站距离;
- 基站接收 UWB 标签接收信号的到达时间(time of arrival,TOA);
- 基站收到的 UWB 标签接收信号强度(received signal strength,RSS)。
其中,距离数据是依托了TOA计算了 UWB 标签位置后获取到的,因此我们着重关注了距离数据与 RSS 数据。同时,考虑到传统视距(line-of-sign,LOS)环境中 UWB 采集的数据可以做到厘米级别的分辨率,因此可以轻松解决高精度测量需求。然而,在复杂的室内环境中,很难保证标签与基站通讯正常进行。因此在特殊的非视距(NLOS)环境,例如室内、狭窄通道等复杂位置下将严重影响距离测量的精度。
为了 UWB 模块在复杂环境实现高精度测量,我们主要在如下的三方面进行了研究与探索。
- LOS/NLOS 的识别与缓解方法:在基站中对数据处理计算部分之前增加了相应程序,这些程序首先确认系统处于 LOS还是 NLOS 环境下,然后基于距离对 NLOS 案例进行测量结果校正,从而提高定位精度。
- 结合距离数据与 RSS 数据:考虑到实际无线信道中的多径效应(Multipath Effect)对实际识别的影响,因此尝试结合距离数据与 RSS 数据,并使用信道的冲击响应(Channel Impulse Response,CIR)来对多径效应进行描述。
- 使用机器学习方法:对人为设计实验条件下的数据进行监督学习,在大量数据的训练下,这些方法在 NLOS 情况下有希望实现提高性能。
然而,上述三种方式都有自己的局限性。
- 大多数 LOS/NLOS 识别和缓解方法都是通过深度学习开发的。在本项目中主要考虑的是动作识别,本质是监视无线信道收扰动后出现的实时 CIR 变化。因此,如果使用复杂的校正方法会在数据计算部分产生延迟,从而导致数据信息滞后,对后面的机器学习模型训练造成极大影响。另一方面,距离数据在本项目中的优先级不高,先通过深度学习获得校正的距离,然后再使用其他方式计算出 CIR 信号的方式是舍近求远了。换句话说,这些方法更适合测距而不是动作识别。
- 脉冲信号通过信道后通常会受到两方面的影响,一是由于路径损耗和阴影衰落造成脉冲信号的能量发生衰减;二是由于信道中存在多个传播路径导致在接收端先后收到多个不同脉冲信号副本的叠加。基于距离和 RSS 的混合算法构建了 NLOS 下的测量模型,尽可能减小了 CIR 的波动。但仍然无法去除稳定环境下的信号波动,且获取的 CIR 数据肉眼难以与对应动作获取联系。
- 许多现有的基于深度学习的方法仅使用距离信息的循环神经网络(Recurrent Neural Network,RNN)网络,而没有考虑到时间与空间特征。此外,在这些方法中几乎没有使用 CIR 信号进行训练分析。
因此,本文为了提高 NLOS 场景下 UWB 模块测量的准确性和鲁棒性,我们使用上述方式,并提出了几个可能的机器学习模型。我们的目的是使用基于传统机器学习和深度学习的策略,利用 CIR 信号学习不同动作的信道扰动特征,进行动作分类。关于机器学习模型,我们尝试了支持向量机(Support Vector Machine,SVM)和端到端的深度学习神经网络。在准备数据集过程中,我们通过滑动窗口(Sliding Window)拼接相邻的数据帧,尝试提取相邻数据前后的潜在联系,建立连续帧之间的相关性。如下图(Fig.1),这也同样对应了动作产生的扰动在连续帧之间的相关性。这些提取的更潜在的时空特征大大帮助了从 CIR 信号提取行为扰动特征的性能。
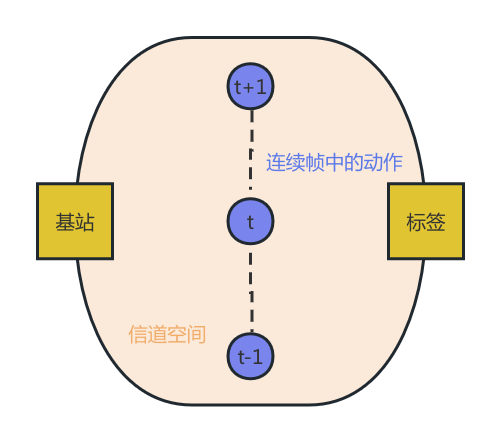
Fig.1 CIR 动作检测连续帧关系。米色的椭球型区域代表了基站与标签之前的相对稳定的信道空间,当在信道空间被运动干扰后,产生的扰动可以反映在 CIR 图谱上。而这里连续的动作点之间的虚线表示连续帧之间的相关性。
本文主要的作用是总结基于 CIR 信号进行动作分类项目的现有进展,以及提出截止目前项目出现的问题与解决方法,并尝试提出未来项目进一步深入研究的方向。
相关工作
由于 STM32 单片机的 UWB 模块已经具备相应的 CIR 数据采集器,因此我们可以直接从基站中通过串口链接获取幅值和相位数据,然后在上位机上合成为 CIR 数据。这里在实际工程中需要注意数据的强制转化为浮点类型,合成公式如下
$$
r = \sqrt{real^2+imag^2}
$$
为了尽可能多地获取到一个短暂动作的连续帧信息,同时也考虑到串口传输的数据带宽限制,我们将 UWB 模块的采样频率设置为 20Hz。因此对于每一个数据帧来说,它都由 100 个整数采样点数据构成。以 1 秒为标准单位,上位机将接收到幅值和相位组合为 CIR 的数据格式为 [20,100],它的实际意义是描述了 1 秒内连续 20 次采样的信道响应输出。我们用 $h[n]$ 代表单位冲击响应通过信道后的结果,$h[n]$ 中的每一个值表示单位脉冲经过对应延时后的衰减和相位变化。假设脉冲通过一个信道产生的最大延时为 M,即在 0 时刻发送的信号,通过信道中最长的传播路径后,可以在时刻 M 到达接收端,这个最大时延又被称为信道时延拓展 。因此对于任意输入信号 $s[n]$,接收端在任意时刻收到的信号实际上是其之前 T 个时刻内发送信号的叠加,即
$$
r[n] = s[n]\times h[0] + s[n-1] \times h[1] + \cdots + s[n-T]\times h[T]\
$$
也可以将上面的式子写成卷积形式
$$
r[n] = \sum_{k=0}^{T}s[n-k]h[k] = s\otimes h
$$
如果模块处于一个稳定的信道空间内,被采集出来的从初始 CIR 信号进行不同延时、不同衰减的线性叠加后的信道响应输出在连续帧内变化有限。但是如果存在扰动源,则连续帧内变化与扰动源有关。同时,不同的扰动源产生的 CIR 信号也具有差异,这也是当前项目研究的基础。
另一方面,如图(Fig.2)我们也搭建了相关的采集数据的实验场地。其中主要的几个动作包括了踢腿(不同速度的踢腿和抬腿)、行走(走向车尾、远离车尾和穿过检测区域)、站立与空场景。且先后进行了个人样本采集、三人样本采集和九人样本采集(各年龄与性别)。在如上的数据样本中我们最关心踢腿样本,因为踢腿动作一方面与行走都有抬腿的过程,同时又和站立等其他动作有差异,且在日常生活中存在作为触发动作的需求(比如踢腿开后备箱门)。因此我们将踢腿作为正样本,其他动作作为负样本进行二分类问题的讨论。
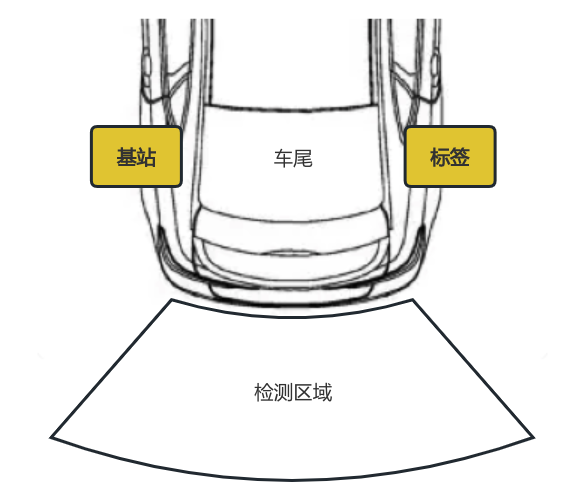

Fig.2 实验布置图。上图为理论布置图,下图为实际布置图。分别将基站和标签固定在车尾的合适位置,经过一段时间,模块附近的信道空间稳定后,在指定扇形区域内进行动作扰动。
在收集数据后,一方面为了更深度地挖掘采集数据的隐藏信息,另一方面训练模型也有对大数据集的需求。因此我们在已采集的样本基础上进行数据样本的扩增。这里的扩增方法遵守这单人单动作单独扩增的要求,方法如图(Fig.3)。在这里可以指定每一次滑动窗口前进的步长,通过调节该参数可以达成不同数量的扩增目的。基于此方法扩增后,可以从 540 个样本扩增到 4500 个数据,为模型训练提供足够的数据基础。
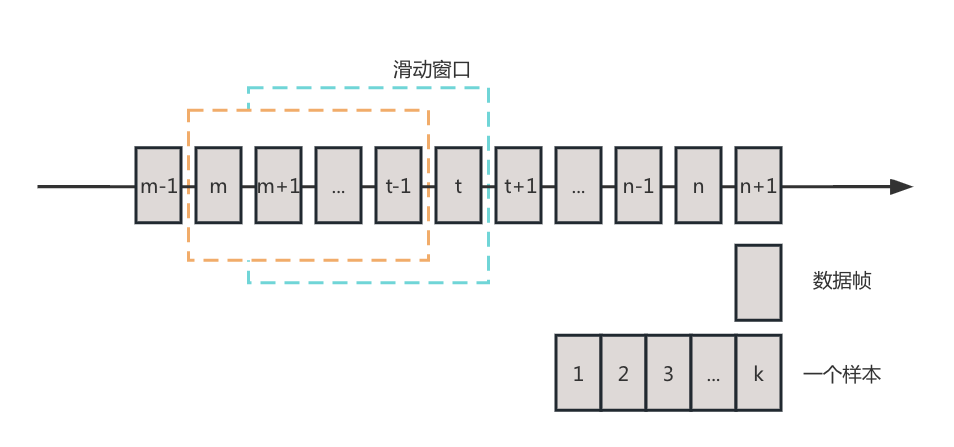
Fig.3 样本扩增示意图。这里一个样本里的 k 是人为更具动作持续时间指定的,代表着一个样本包含的数据帧数量。
然而在前期处理数据的时候,由于输入数据的维度过高导致我们最初的传统模型效果并不好。因此,我们考虑使用主成分分析(Principal components analysis,PCA)进行降维,从而尝试摆脱维度爆炸。具体来说,pca 本质上是一个正交化线性变换,将原数据方差按大小分别投影到不同维度(主成分)上。定义一个 $n \times m$ 矩阵,$X^T$ 为去平均值数据。则 $X$ 的奇异值分解为 $X=W\Sigma V^T$,据此 pca 数学可以表示为
$$
Y^T=X^TW=V\Sigma^TW^TW=V\Sigma^T
$$
其中 $Y^T$ 的第一列代表第一主成分组,第二列代表第二主成分组,以此类推。而关于众多成熟的 pca 方法中,我们主要使用了 scikit-learn 的 主成分分析(PCA)、稀疏主成分分析(SparsePCA)、内核主成分分析(KernelPCA)、增量主成分分析(IncrementalPCA)、Mini-batch 稀疏主成分分析(MiniBatchSparsePCA)封装方法。而一般情况下,在 pca 之前我们还会添加标准化部分,以符合 scikit-learn 中实现许多机器学习估计器的普遍要求,达到提高性能的要求。这里的标准化也同样是手机用 scikit-learn 中自带的标准化方法 StandardScaler,也可以方便地和后面的步骤组成管道(pipeline)进行一步式处理。
本项目中模型训练方法使用 k 折交叉验证法(k-fold cross-validation),将训练集分割成 k 个子集,每一个子集对应一个人的全部动作,而其中一个单独的子集被保留作为验证模型的数据,其他 k − 1 个子集用来训练。交叉验证重复 k 次,每个子集验证一次,平均 k 次的结果,最终得到一个单一估测。这个方法的优势在于,一次性使用了单个人的全部样本,分离了不同人之间的数据,在模型预测时候可以更加好地表现模型的鲁棒性。
实验模型
经过目前的测试,SVM 和神经网络的效果比较好。在我们的项目中使用了来自 scikit-learn 的 SVM 模型,且在小样本、传统机器学习模型环境内测试效果优秀,如表(Table 1)。具体来说在 SVM 模型部分,我们尝试在训练前对数据进行 spare pca 降维到 5 维数据,凭借这个方法获取到更高的准确率和更好的 FP。
Tabel 1 各个传统模型在 3 人 4 动作数据集上的效果(仅选择部分 acc 70 以上的模型)。这里的 N 代表帧格式截取前部分的数量,例如 65 代表一帧中的 100 个数据只取前 65 个;这里的 FP 是指将其他动作分类为踢腿样本的数量。
| 模型名 | 模型参数 | 准确率 | FP |
|---|---|---|---|
| SVM | N=65,gamma=9e-4,C=1 | 70.37% | 50 |
| SVM | N=65,gamma=9e-4,C=1,spare pca(dim=5) | 73.52% | 28 |
另一方面,我们在 9 人 5 动作的新数据集上发现仅使用传统机器学习模型获取的可用信息有限,同时如果不对输入的数据量加以限制会导致模型训练成本暴增、模型性能下降等问题。因此我们考虑通过神经网络方式来解决该问题。
Table 2 神经网络模型在 9 人 5 动作数据集上的效果。以下模型共有的模型参数 batch size=128、lr=1e-3、epoch=100、optimizer=Adam、loss=cross_entropy_loss。这里的 FPR 是指将其他动作分类为踢腿样本的数量占全部样本的比例。
| 模型名 | 输入样本形状 | 准确率 | FPR | 验证集准确率 | 验证集FPR | |
|---|---|---|---|---|---|---|
| FC | shape=[[0,40],[0,70]] | 82.73% | 17.62% | 89.05% | 12.86% | |
| FC | shape=[[0,40],[0,75]] | 85.26% | 14.98% | 88.90% | 6.42% | |
| FC | shape=[[0,40],[3,70]] | 81.34% | 18.61% | 89.51% | 8.90% | |
| FC | shape=[[0,40], [5,70]] | 86.49% | 13.87% | 88.78% | 10.37% |
详细来说,利用神经网络中的全连接网络(Fully-connected network,FC),对样本进行展平输入模型中,然后输出 2 个参数的预测结果,代表了二分类的概率结果。在目前的理论测试环境中,已经可以达到一个相对满意的结果。
总结
目前项目的实验数据较为优异,但是在实地部署测试结果非常糟,无法正常使用。可能的原因有如下几个:
- 采集训练数据的环境、UWB 模块位置等与实地部署时不同,造成在稳定信道下的 CIR 波形有差异;
- 在实地部署时很难让模块工作在稳定信道中,任何的扰动都会造成 CIR 信号波动。简单来说,类似于混沌系统;
- 在采集数据时由于连续采集导致串口持续在最大带宽附近工作,同时由于高频率读写使得缓存区内数据累计,如果采集前缓存区内已经存在部分数据,长时间读取数据会造成读取的幅值和相位数据错位。
目前已经通过修改采集代码暂时解决了数据对齐问题,而很难排除其他两个环境方面的问题对实验的影响。另一方面,我们也有如下几个未来实验探索的方向:
- 将 CIR 数据可视化处理,例如变换为图片然后再通过成熟的图像识别方法进行动作识别;
- 对 CIR 数据进行滤波方面的研究,尽可能降低环境扰动对 CIR 信号的干扰;
- 使用其他更加复杂模型,同时尝试模型融合方式;
- 在预测模型的基础上,在外侧加上一个异常检测模型,来判断读入样本的数据是否是正常样本。
本文写在项目第一阶段结束后,旨在总结项目研究过程中获取的成果、不足与遗憾,并对未来的研究第二阶段铺下基础。
