.jpg)
数据挖掘:作业 09
数据挖掘:实验九 特征选择
代码地址:Github
实验目的和要求
通过在Python中的实例应用,分析掌握利用特征选择算法进行数据挖掘的基本原理,加深对特征选择算法的理解,并掌握将算法应用于实际的方法、步骤
实验内容和原理
- 通过实际例子理解特征选择算法的基本原理,加深对算法的理解
- 在Python中实现特征选择算法的数据输入、参数设置以及对结果进行分析
操作方法和实验步骤
- 针对数据集german_clean,随机采样100次,利用Relief方法,给出特征重要性程度的排序。
- 结合第1步得到的特征重要性排序,将数据集的前700个数据作为训练集,后300个数据作为验证集,给出用Logistic回归方法进行分类的最佳特征子集。(注意数据集目标字段的标签是用1,2来表示,要修改成0,1)
实验结果和分析
Answer01
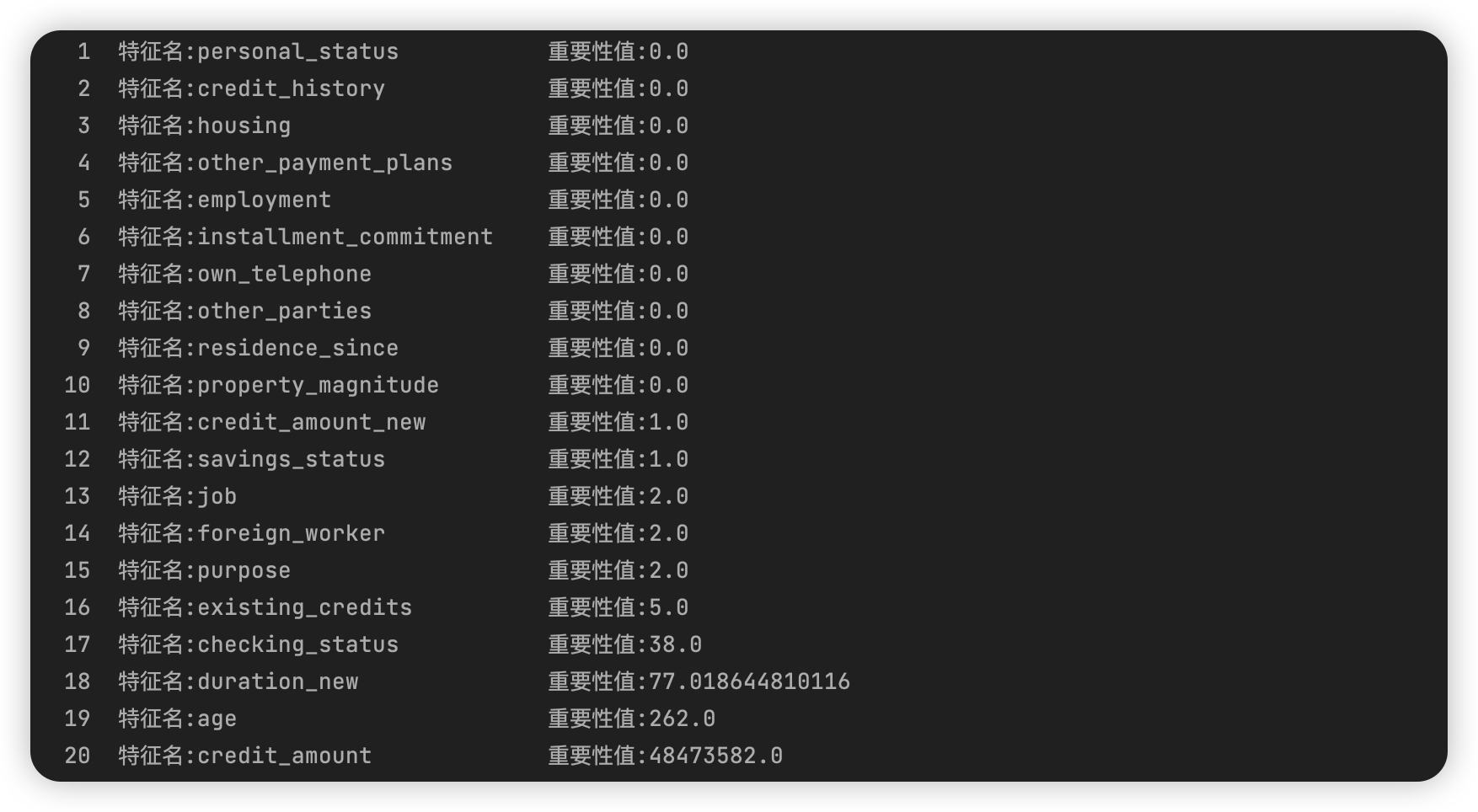
Answer02


使用手机访问这篇文章
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Owen

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果