.jpg)
数据挖掘:大作业
数据挖掘大作业报告
问题描述
赛题背景简介
巴西支付品牌Elo

- 本次竞赛其实是由巴西最大的支付品牌之一的Elo和Kaggle合作举办的比赛,奖金和数据都由Elo公司提供。谈到支付品牌,国内用户首先会想到类似支付宝、PayPal这些带有浓烈互联网色彩的支付品牌,但是在巴西,线上支付更多是由本地银行主导,且线上支付的信贷产品也主要以信用卡为主。Elo就是这样的一家公司,在2011年由巴西三家主要银行合资创立,主要负责线上支付业务,并且以信用卡作为核心金融产品,目前已发放超过1.1亿张信用卡,是巴西最大的本地在线支付品牌之一。并且,Elo不仅是支付入口,更是一个“o2o”平台,通过App,用户可以查阅本地餐饮旅馆电影旅游机票等各项服务,并支持信用卡在线支付。形象点理解,就好比把美团主页移到支付宝,并且支付宝没有花呗,取而代之的是自己发行的信用卡。或者更加形象的理解,就类似国内招行信用卡掌上生活的业务模式
- 借助论坛挖掘更多信息
- 对于Elo来说,其实是有一套计算用户忠诚度的公式的,这也就是标签的由来。因此我们在进行建模的时候实际上是为了建立一套计算过程,尽可能逼近这个公式的计算结果;
- 通过简单尝试不难发现,Elo内部计算忠诚度的公式极有可能完全不是我们现在看到的这些字段,也就是说我们需要使用另一套字段去尽可能还原Elo内部计算忠诚度的过程;
- 忠诚度评分如何影响精准推荐,这个过程极有可能类似游戏匹配机制,即不同分数段、不同战绩有可能匹配到不同的对手,而本次竞赛中其实只有关于用户一方分数的计算。
目标
- 业务目标:更好的进行本地服务推荐
- 在官方给出的说明中,我们不难发现,Elo使用机器学习算法技术的核心目的,是为了更好的在App内为用户推荐当地吃穿住行的商家服务,包括热门餐厅展示、优惠折扣提醒等(非常类似上图掌上生活首页的推荐)。也就是说,其根本目的是为了推荐,或者说为每个用户进行更加个性化的推荐,也就是赛题标题中的所写的:Merchant Category Recommendation(商户类别推荐)。但是,需要注意的是,本次竞赛的建模目标却和推荐系统并不直接相关。赛题说明中,在介绍完业务目标之后,紧接着就介绍了本次赛题的目标:对用户的忠诚度评分进行预测。
- 算法目标:用户忠诚度评分预测
- 所谓用户忠诚度评分,通过后续查看Evaluation不难发现,其实就是对每个用户的评分进行预测,本质上是个回归问题。
- 围绕这个问题,赛题说明给出了非常笼统的解释,只是简单说到通过对用户忠诚度评分,能够为其提供最相关的机会(serve the most relevant opportunities to individuals),或者可以理解成是用户较为中意的线下服务,并且帮助ELo节省活动成本,为用户提供更好的体验。其实也就等于是没有解释忠诚度评分和推荐系统到底是什么关系。Kaggle本赛题论坛上也有很多相关讨论帖,官方给出的解释大意是通过忠诚度评分给用户推荐商铺和商品,这个过程并不是一个传统的协同过滤或者推荐系统进行推荐的过程,无论如何,先做好忠诚度预测就好。
数据解读与初步探索
数据字典解读
train 表
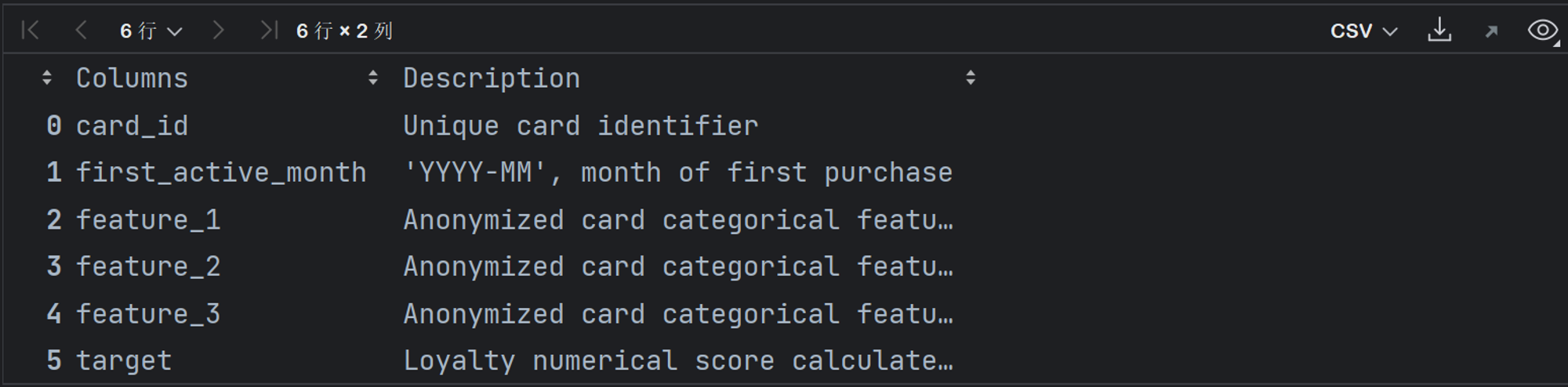
sample_submission(正确提交结果范例)表
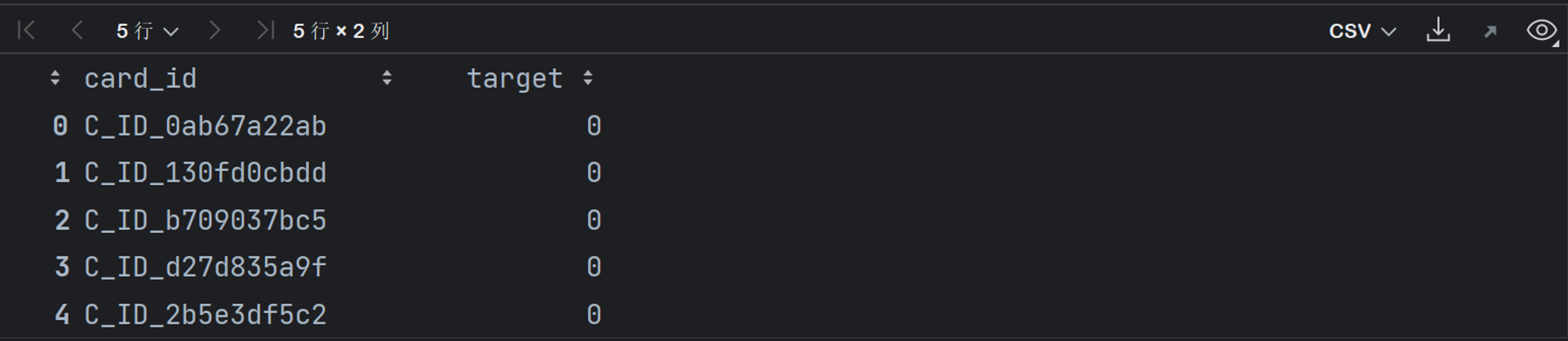
最终建模结果提交格式,也就是以“一个id”+“对应预测结果”的格式进行提交。据此我们也能发现,实际上我们是需要预测每个card_id的用户忠诚度评分。
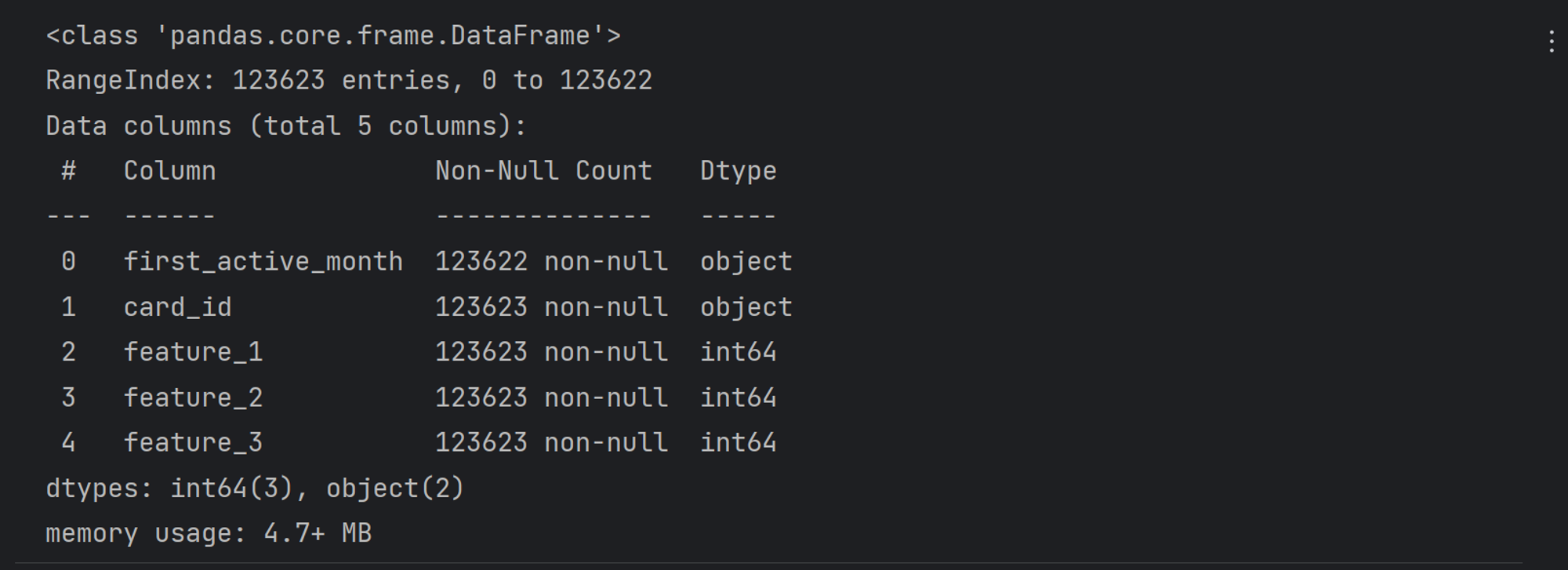
train 和 test 数据集解读初步探索
train:训练数据集
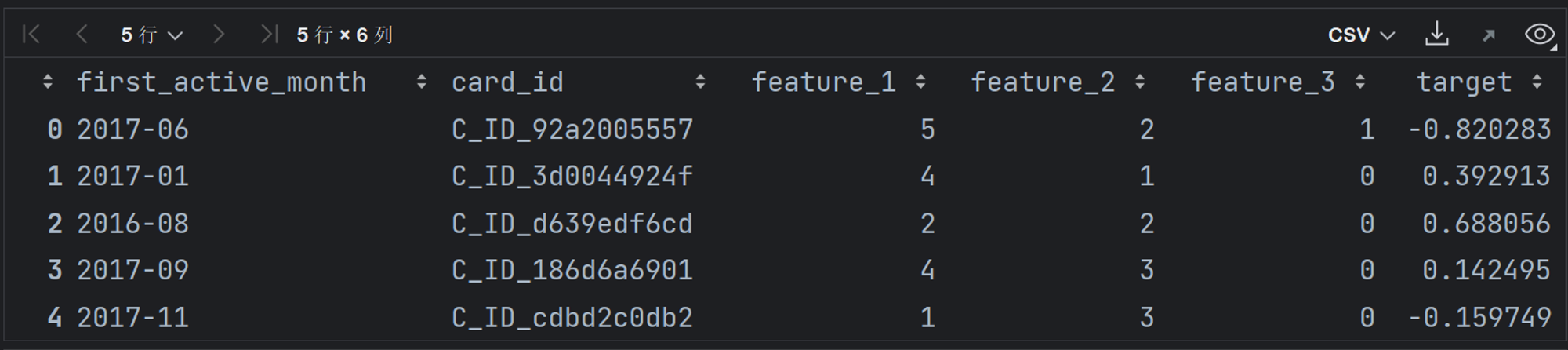

回顾数据字典中的train表,查看train数据集中各字段解释,实际含义如下:
| 字段 | 解释 |
|---|---|
| card_id | 第一无二的信用卡标志 |
| first_active_month | 信用卡首次激活时间,按照类似2017-02排列 |
| feature_1/2/3 | 匿名特征(不带明显业务背景或人工合成的特征) |
| target | 标签,忠诚度评分 |
test:测试数据集
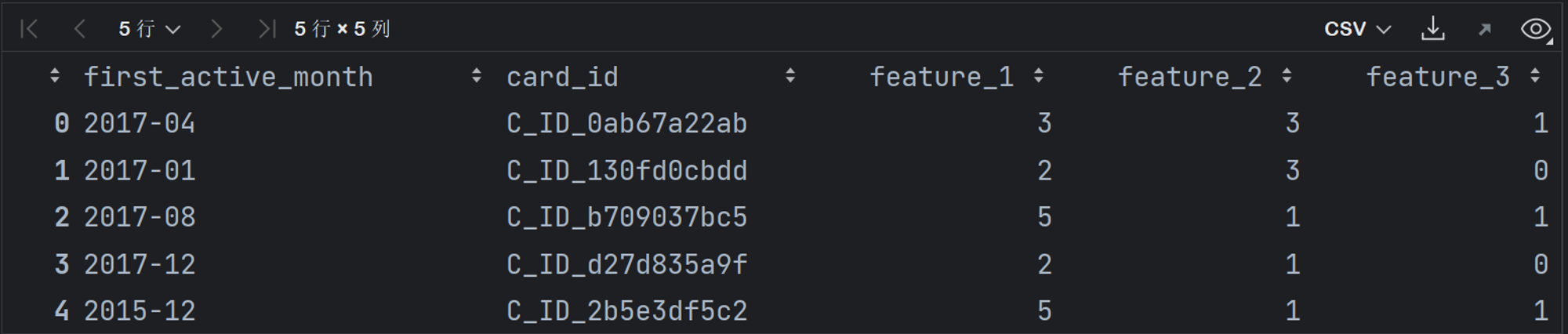
并且各字段的解释和train一致。实际比赛过程中,由于测试集的标签“不可知”,所以需要在训练集train上划分出验证集来进行模型泛化能力评估。
数据质量分析
(1)数据正确性校验
- 所谓数据正确性,指的是数据本身是否符合基本逻辑,例如此处信用卡id作为建模分析对象独一无二的标识,我们需要验证其是否确实独一无二,并且训练集和测试集信用卡id无重复。
- True True True
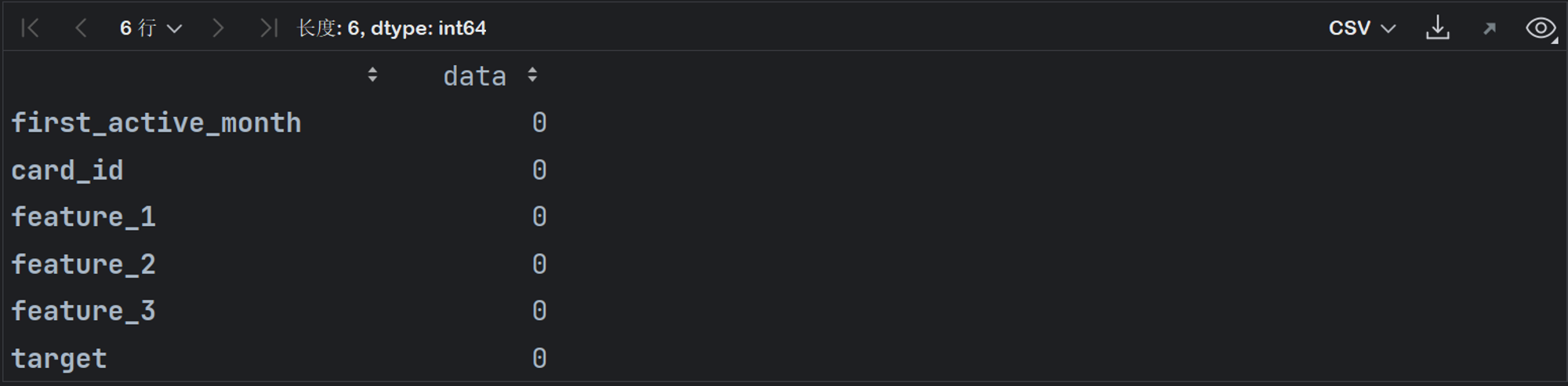
(2)检验数据缺失情况
- 能够发现数据集基本无缺失值,测试集中的唯一一个缺失值我们可以通过多种方式来进行填补,整体来说一条缺失值并不会对整体建模造成太大影响。
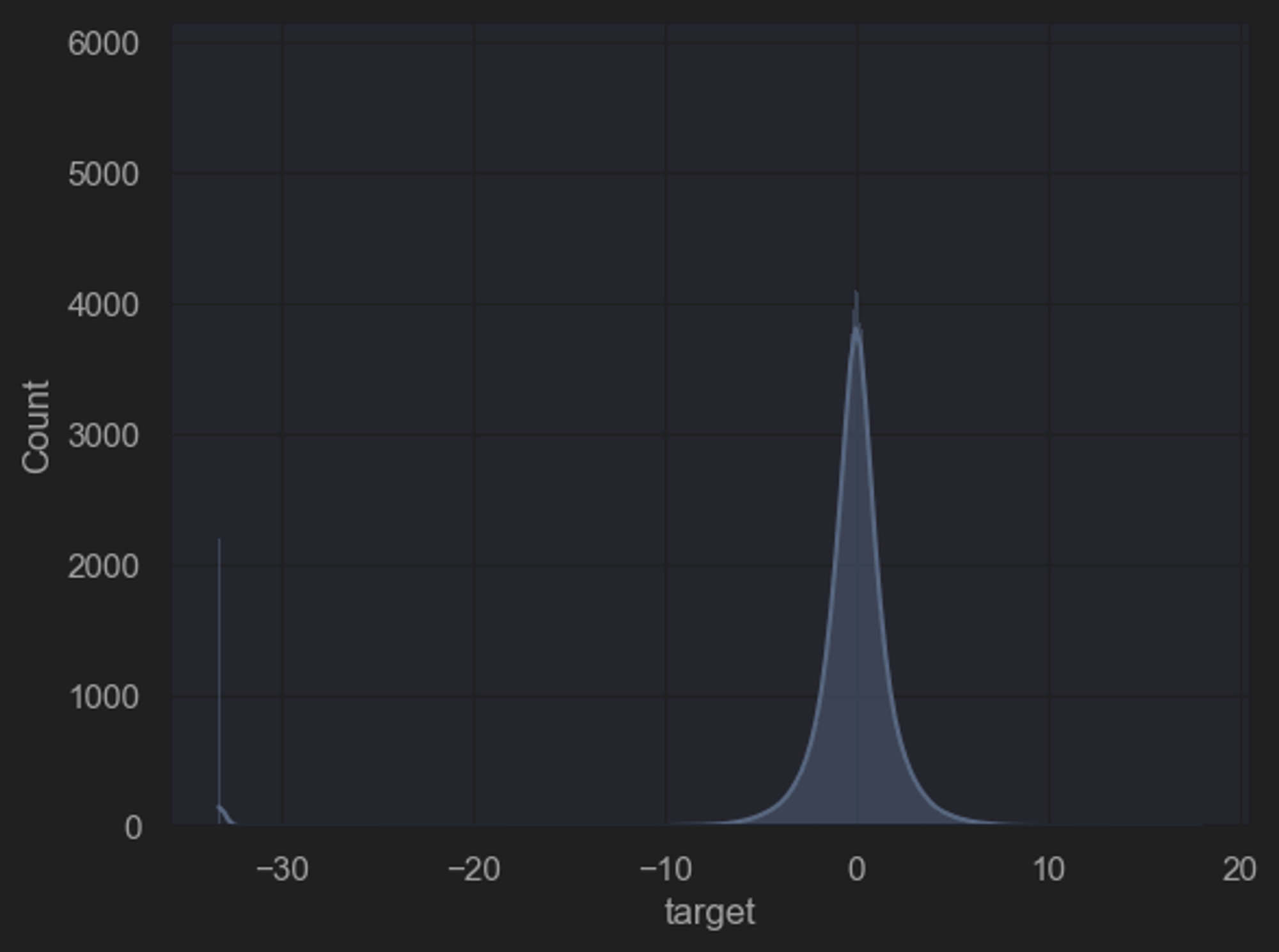
(3)异常值
- 需要注意的是,此处我们是围绕标签进行的异常值检测,而本案例中标签并不是自然数值测量或统计的结果(如消费金额、身高体重等),而是通过某种公式人工计算得出(详见赛题分析)。出现如此离群点极有可能是某类特殊用户的标记。因此不宜进行异常值处理,而应该将其单独视作特殊的一类,在后续建模分析时候单独对此类用户进行特征提取与建模分析。
(4)规律一致性分析——单变量分析
-
所谓规律一致性,指的是需要对训练集和测试集特征数据的分布进行简单比对,以“确定”两组数据是否诞生于同一个总体,即两组数据是否都遵循着背后总体的规律,即两组数据是否存在着规律一致性。
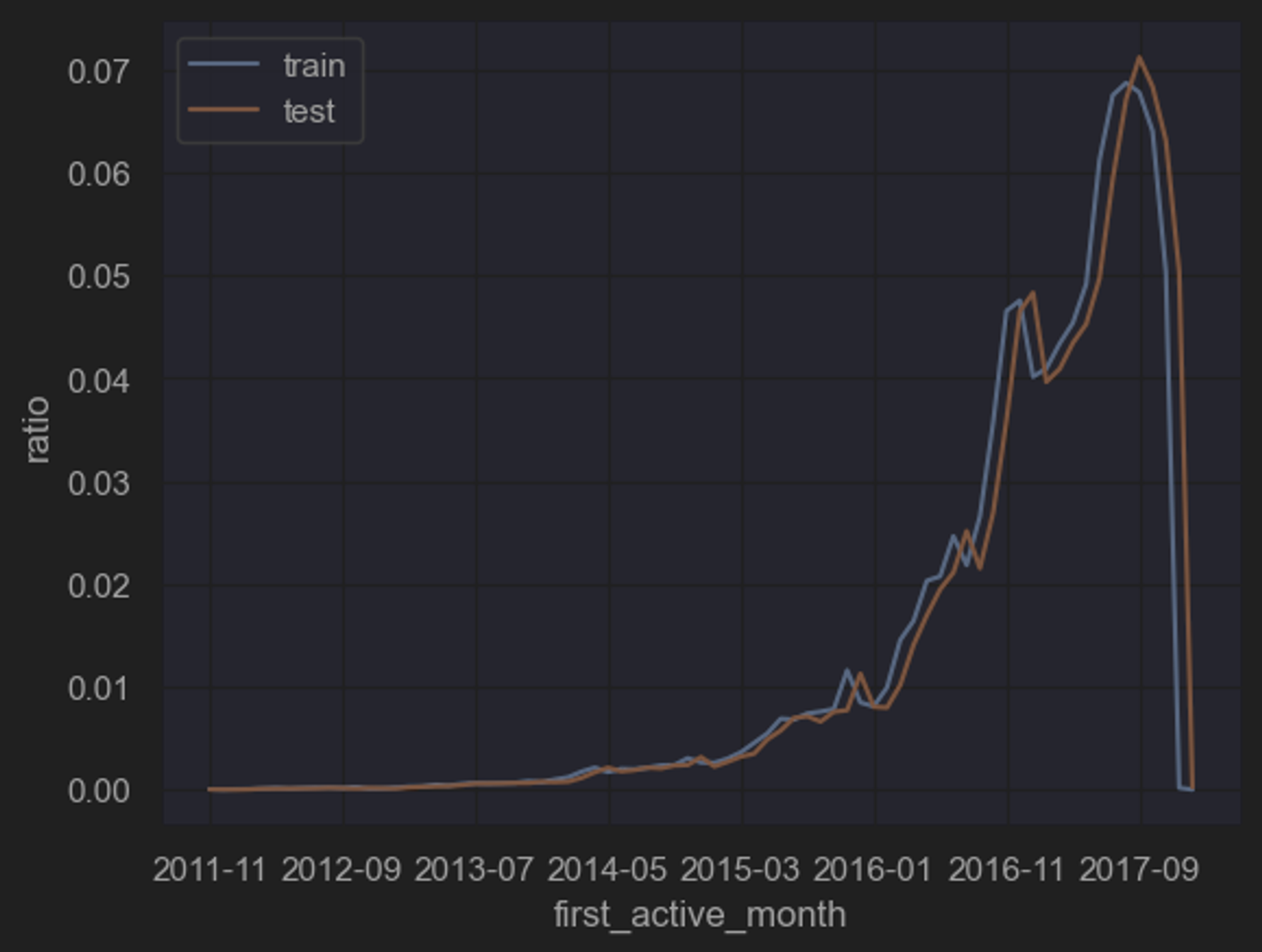
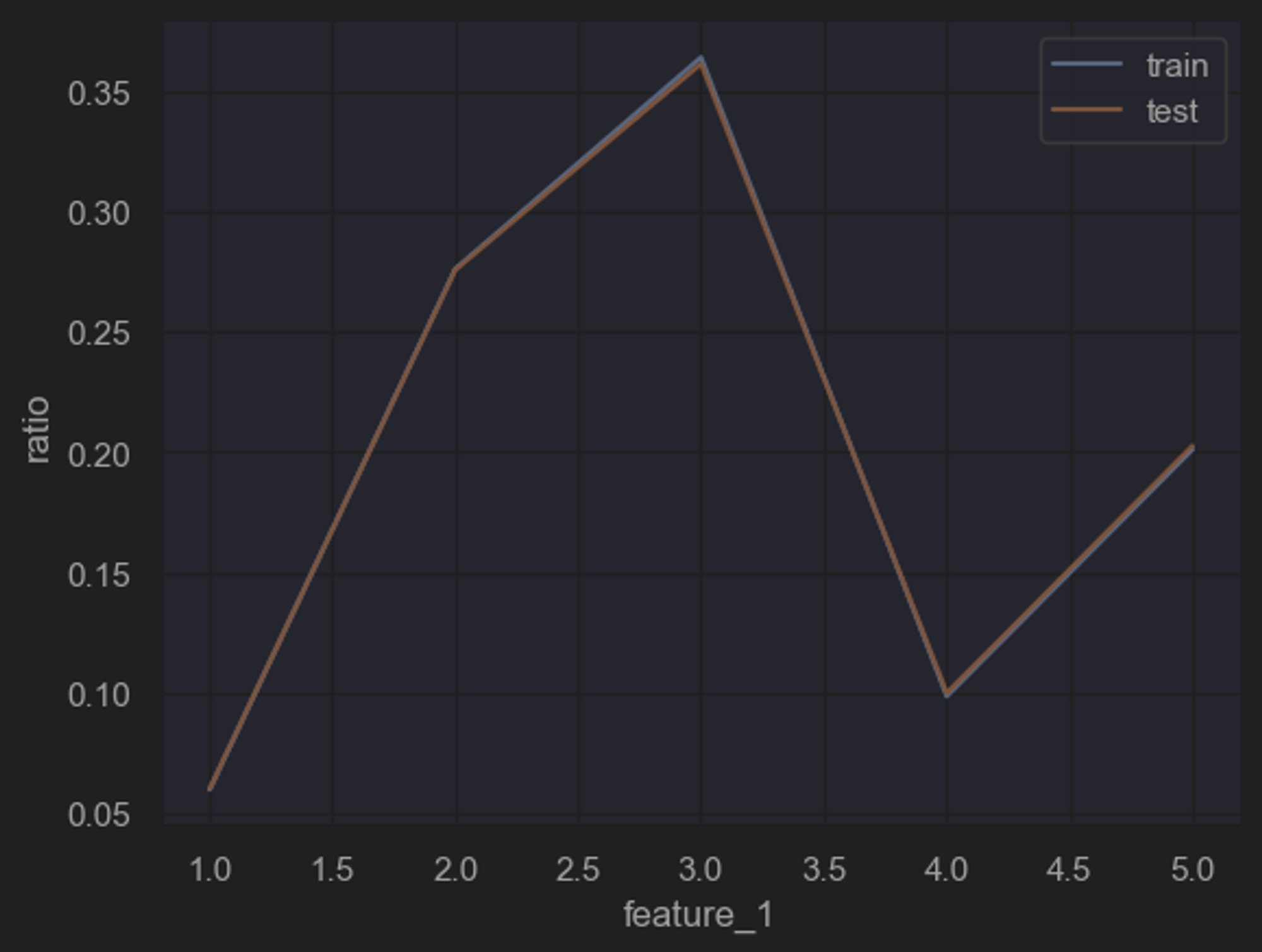
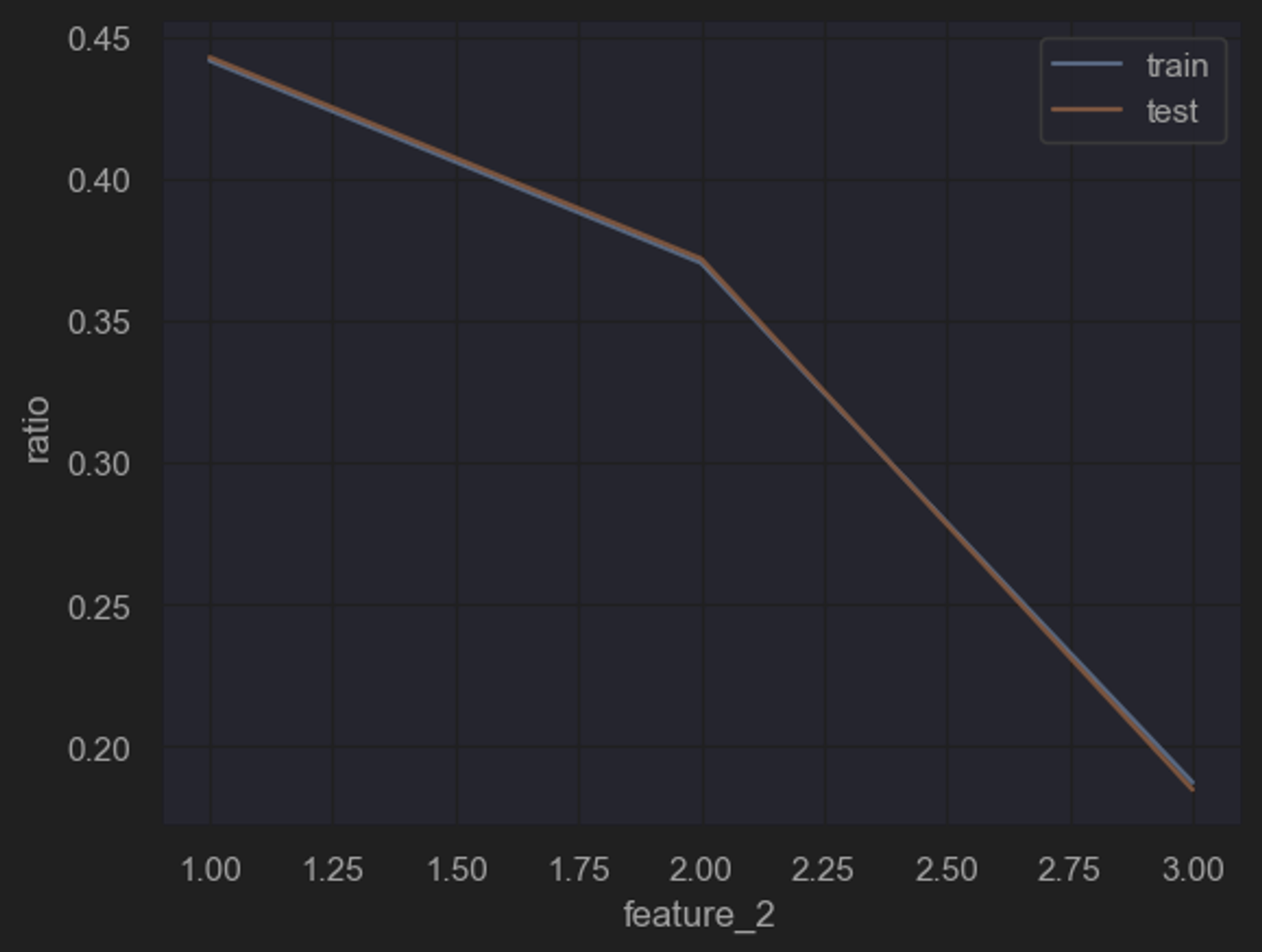
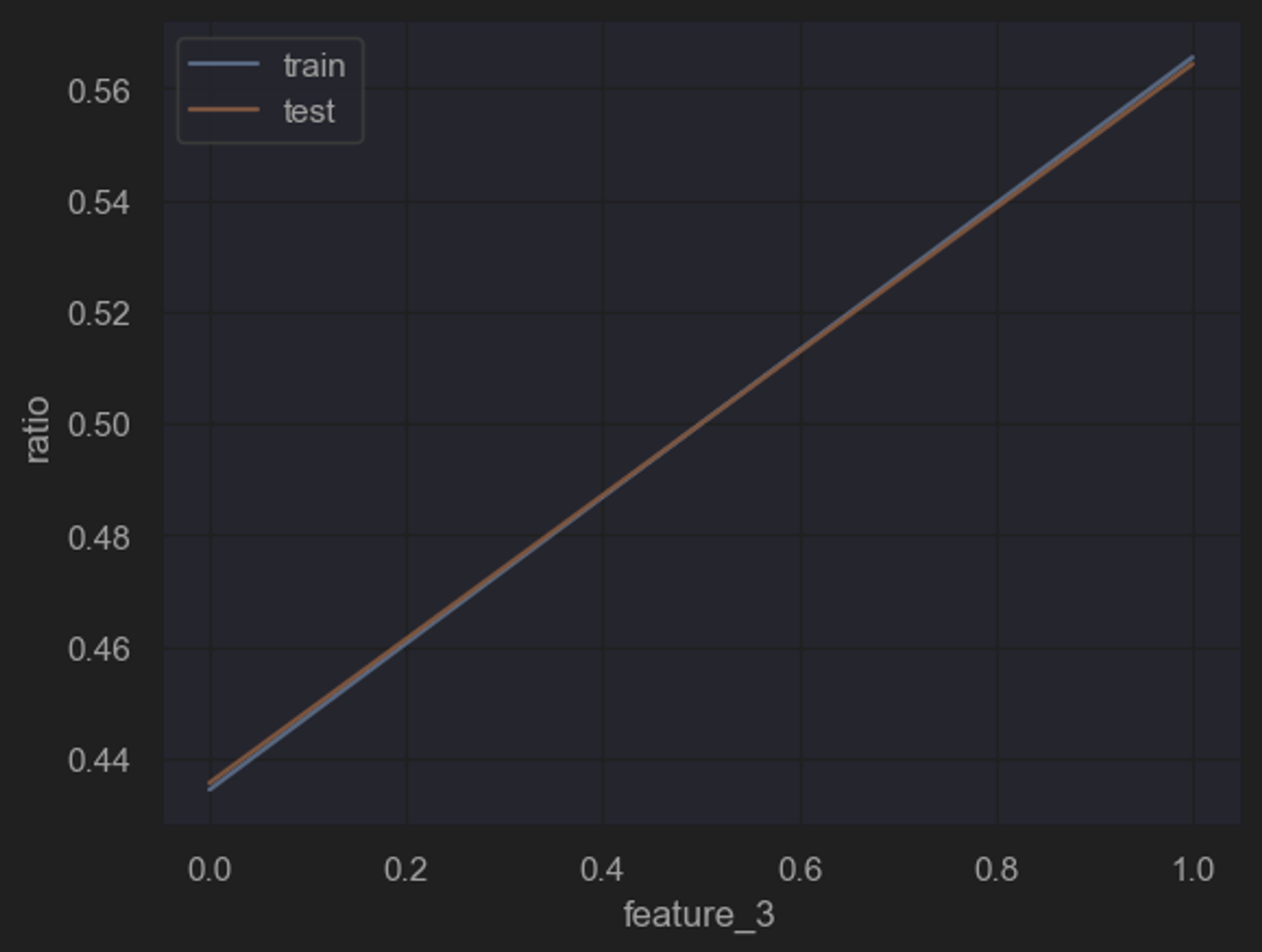
能够发现,两组数据的单变量分布基本一致。
(5)规律一致性分析——多变量联合分布
-
所谓联合概率分布,指的是将离散变量两两组合,然后查看这个新变量的相对占比分布。例如特征1有0/1两个取值水平,特征2有A/B两个取值水平,则联合分布中就将存在0A、0B、1A、1B四种不同取值水平,然后进一步查看这四种不同取值水平出现的分布情况。
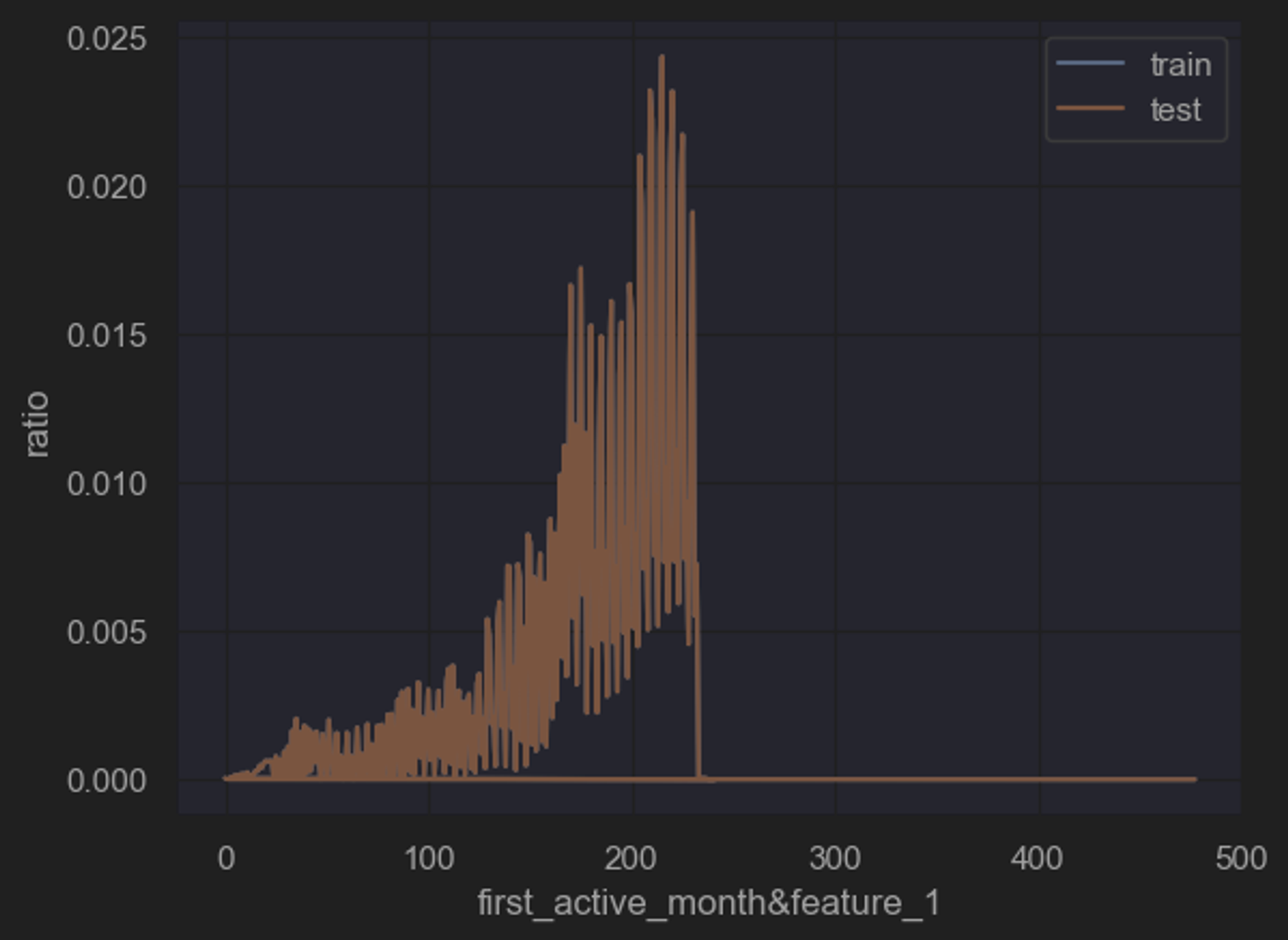
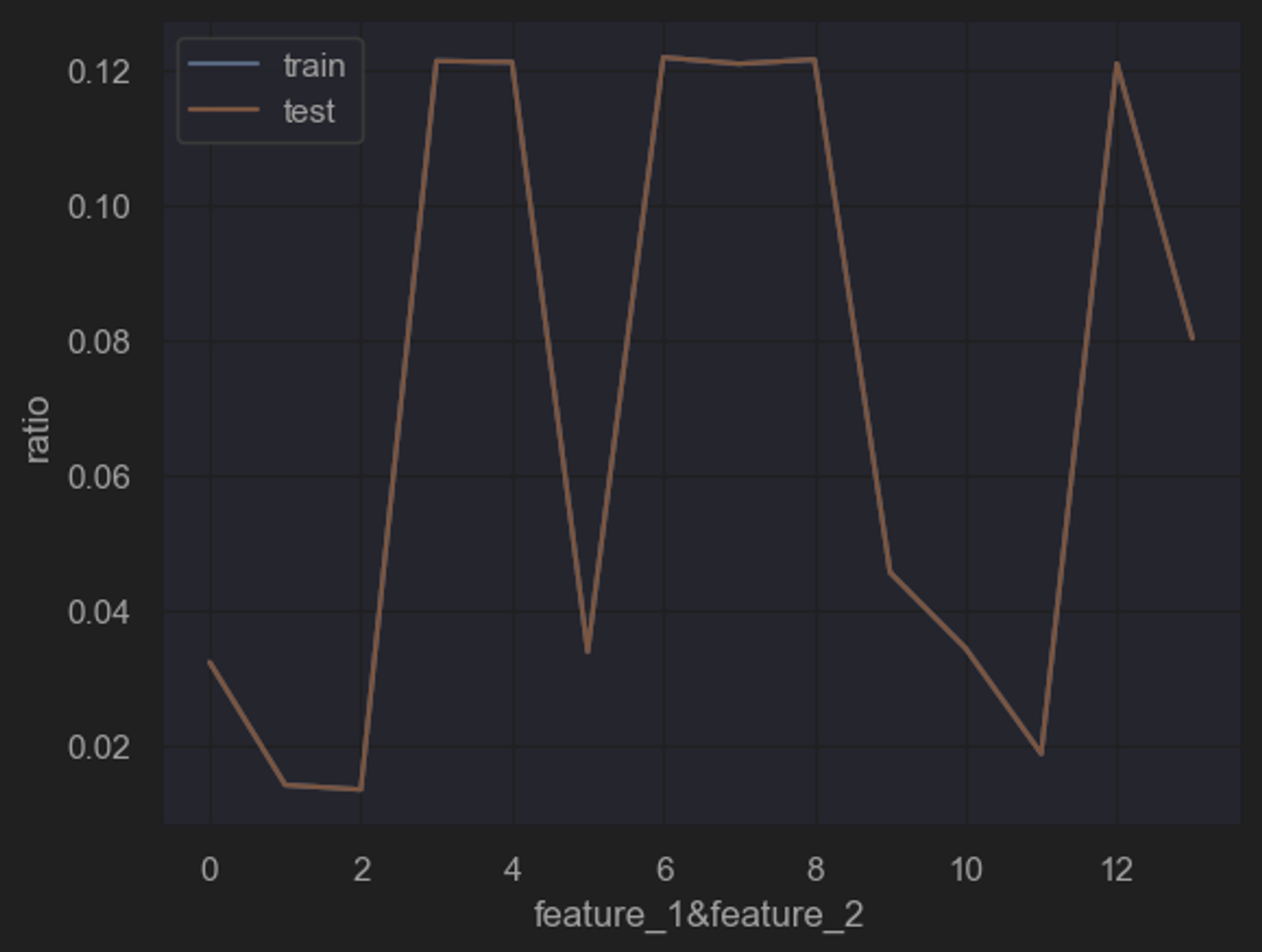
能够发现所有联合变量的占比分布基本一致。数据集整体质量较高,且基本可以确认,训练集和测试集取自同一样本总体。
商户数据解读与探索
数据解读:merchants.csv
数据集基本字段的实际含义如下:
| 字段 | 解释 |
|---|---|
| merchant_id | 商户id |
| merchant_group_id | 商户组id |
| merchant_category_id | 商户类别id |
| subsector_id | 商品种类群id |
| numerical_1 | 匿名数值特征1 |
| numerical_2 | 匿名数值特征2 |
| category_1 | 匿名离散特征1 |
| most_recent_sales_range | 上个活跃月份收入等级,有序分类变量A>B>...>E |
| most_recent_purchases_range | 上个活跃月份交易数量等级,有序分类变量A>B>...>E |
| avg_sales_lag3/6/12 | 过去3、6、12个月的月平均收入除以上一个活跃月份的收入 |
| avg_purchases_lag3/6/12 | 过去3、6、12个月的月平均交易量除以上一个活跃月份的交易量 |
| active_months_lag3/6/12 | 过去3、6、12个月的活跃月份数量 |
| category_2 | 匿名离散特征2 |
数据表中提供不仅提供了商户的基本属性字段(如类别和商品种群等),同时也提供了商户近期的交易数据。不过和此前一样,仍然存在大量的匿名特征。
数据探索
- 正确性校验
- 该表并不是一个id对应一条数据,存在一个商户有多条记录的情况。且商户特征完全一致。
- 缺失值分析
- 能够发现,第二个匿名分类变量存在较多缺失值,而avg_sales_lag3/6/12缺失值数量一致,则很有可能是存在13个商户同时确实了这三方面信息。其他数据没有缺失,数据整体来看较为完整。
数据预处理
- 离散变量的缺失值标注
- 注意到离散变量中的category_2存在较多缺失值,由于该分类变量取值水平为1-5,因此可以将缺失值先标注为-1,方便后续进行数据探索:
- 离散变量字典编码
- 接下来对离散变量进行字典编码,即将object对象类型按照sort顺序进行数值化(整数)编码。例如原始category_1取值为Y/N,通过sort排序后N在Y之前,因此在重新编码时N取值会重编码为0、Y取值会重编码为1。以此类推。
- 需要注意的是,从严格角度来说,变量类型应该是有三类,分别是连续性变量、名义型变量以及有序变量。连续变量较好理解,所谓名义变量,指的是没有数值大小意义的分类变量,例如用1表示女、0表示男,0、1只是作为性别的指代,而没有1>0的含义。而所有有序变量,其也是离散型变量,但却有数值大小含义,如上述most_recent_purchases_range字段,销售等级中A>B>C>D>E,该离散变量的5个取值水平是有严格大小意义的,该变量就被称为有序变量。
- 在实际建模过程中,如果不需要提取有序变量的数值大小信息的话,可以考虑将其和名义变量一样进行独热编码。但本阶段初级预处理时暂时不考虑这些问题,先统一将object类型转化为数值型。
- 连续变量数据的无穷值处理
- 此处我们首先需要对无穷值进行处理。此处我们采用类似天花板盖帽法的方式对其进行修改,即将inf改为最大的显式数值。
- 连续变量数据的缺失值处理
- 不同于无穷值的处理,缺失值处理方法有很多。但该数据集缺失数据较少,33万条数据中只有13条连续特征缺失值,此处我们先简单采用均值进行填补处理,后续若有需要再进行优化处理。
信用卡交易数据解读与探索
数据解读:historical_transactions
数据集总共包括将近三千万条数据,总共有十四个字段,每个字段在数据字典中的解释如下:
| 字段 | 解释 |
|---|---|
| card_id | 第一无二的信用卡标志 |
| authorized_flag | 是否授权,Y/N |
| city_id | 城市id,经过匿名处理 |
| category_1 | 匿名特征,Y/N |
| installments | 分期付款的次数 |
| category_3 | 匿名类别特征,A/.../E |
| merchant_category_id | 商户类别,匿名特征 |
| merchant_id | 商户id |
| month_lag | 距离2018年月的2月数差 |
| purchase_amount | 标准化后的付款金额 |
| purchase_date | 付款时间 |
| category_2 | 匿名类别特征2 |
| state_id | 州id,经过匿名处理 |
| subsector_id | 商户类别特征 |
对比merchant数据集:
- 并且我们进一步发现,交易记录中的merhcant_id信息并不唯一; 造成该现象的原因可能是商铺在逐渐经营过程动态变化,而基于此,在后续的建模过程中,我们将优先使用交易记录中表中的相应记录。
数据预处理
- 连续/离散字段标注
- 字段类型转化/缺失值填
- 和此前的merchant处理类似,我们对其object类型对象进行字典编码(id除外),并对利用-1对缺失值进行填补
数据清洗后数据生成

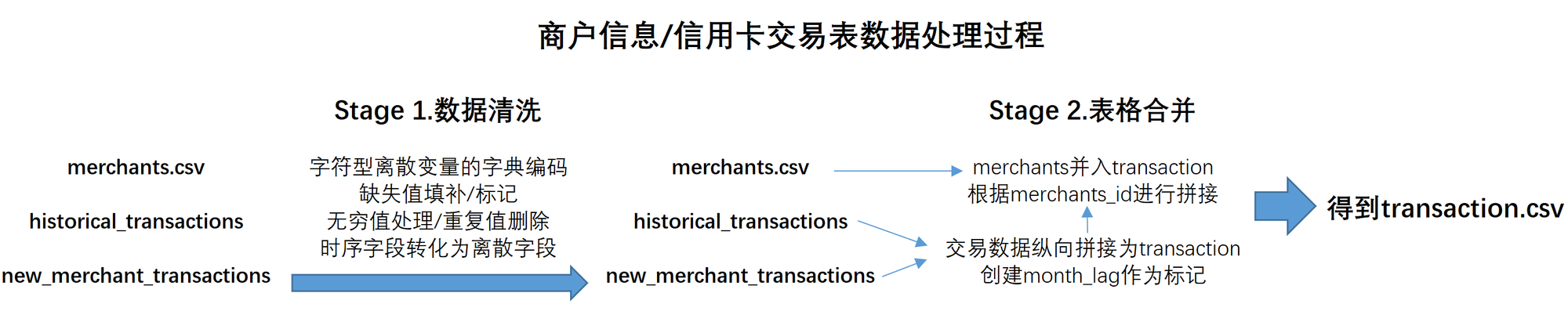
特征工程与模型训练
特征工程
通用组合特征创建
通用组合特征的创建方法:
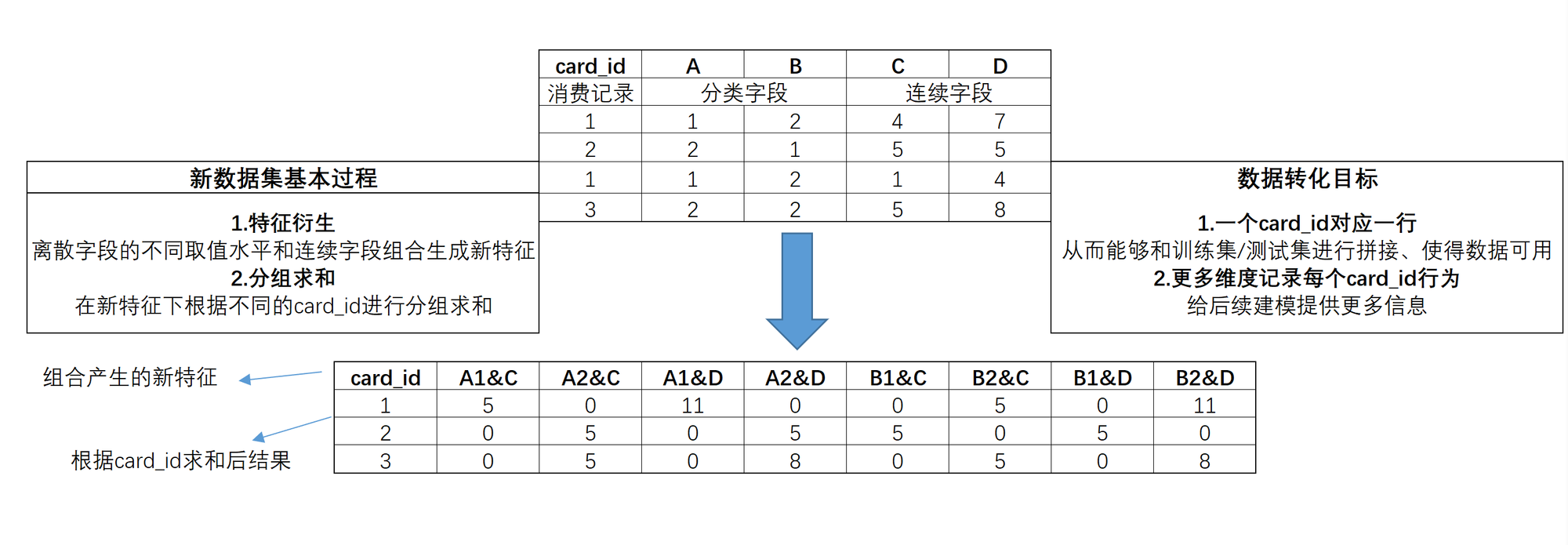
基于transaction数据集创建通用组合特征:
业务统计特征创建
业务统计特征创建方法:
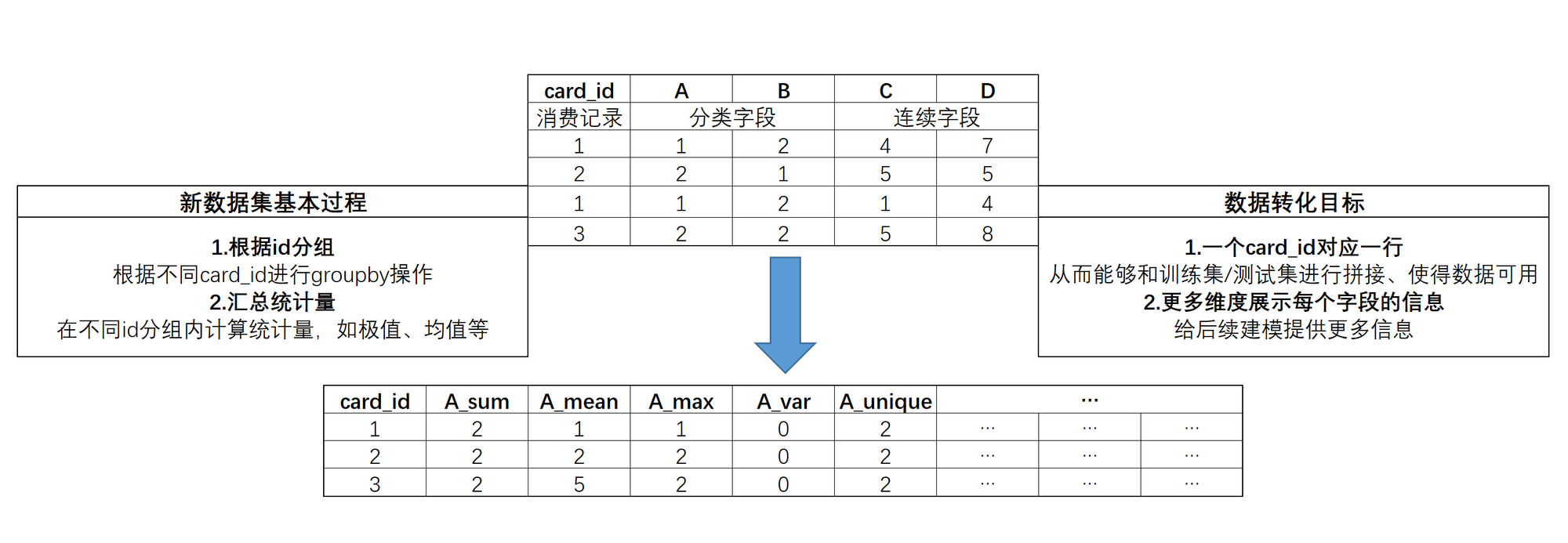
基于transaction数据集创建业务统计特征:
数据合并
至此,我们即完成了从两个不同角度提取特征的相关工作。不过截至目前上述两套方案的特征仍然保存在不同数据文件中,我们需要对其进行合并,才能进一步带入进行建模,合并过程较为简单,只需要将train_dict(test_dict)与train_group(test_group)根据card_id进行横向拼接、然后剔除重复列即可。
随机森林模型预测
特征选择
借助皮尔逊相关系数,挑选和标签最相关的300个特征进行建模。
借助网格搜索进行参数调优
海量特征池衍生策略与Baseline创建
Filter 特征筛选
Filter 特征筛选思路及方法
- 在特征总数较多且特征矩阵较为稀疏时,需要考虑在模型训练前进行特征筛选。我们知道,树模型及树模型的集成模型存在一定的特征筛选机制,即每棵树在进行训练的时候会优先选择能最大程度提升子集纯度的特征进行划分,但当特征太多时,尽管最终结果不一定会受到冗余(无用)特征影响,但模型效率会大幅降低,因此面对树模型及树模型的集成模型,我们仍然需要考虑在实际建模前进行特征筛选,优先带入有效特征进行建模。
- 而一般来说,特征筛选的方式主要有两类,其一是通过某些统计量对特征进行评估,在实际模型训练开始之前挑选出那些更加有效的特征并最冬完成筛选,例如我们可以通过相关系数计算,判断特征和标签之问的相关关系, 后选取相关系数较大的特征带入进行建模,这种方法也被称为Fiter方法:此外,我们也可以通过模型来筛选有效特征,例如随机森林模型可以输出特征重要性,我们可以先快速训练一个随机森林模型,然后根据输出的特征重要性,饰选更重要的特征带入后续超参數优化及交叉验证过程(需要知道的是,对于单独一个楼型來说,是否带入冗余特征对单次训练来说影响不大,但由于超参数优化和交叉验证需要重复进行多轮训练,此时冗余特征的影响就会指数级上升),这样的特征筛选过程也被称:Wrapper过程。
Filter相关系数特征筛选过程
集成学习与模型融合
Wrapper特征筛选 + LightGBM建模 + TPE调优
使用Wrapper方法进行特征筛选,通过带入全部数据训练一个LightGBM模型,然后通过观察特征重要性,选取最重要的300个特征。为了进一步确保挑选过程的有效性,此处我们考虑使用交叉验证的方法来进行多轮验证。
单模型检测
能够发现,在单模型预测情况下,lgb要略弱于rf,接下来考虑进行交叉验证,以提高lgb模型预测效果。
结合交叉验证进行模型预测
和随机森林借助交叉验证进行模型预测的过程类似,lgb也需要遵照如下流程进行训练和预测,并同时创建后续集成所需数据集以及预测结果的平均值(作为最终预测结果)
NLP特征优化 + XGBoost建模 + 贝叶斯优化器
考虑采用CountVectorizer, TfidfVectorizer两种方法对数据集中部分特征进行NLP特征衍生,并且采用XGBoost模型进行预测,同时考虑进一步使用另一种贝叶斯优化器(bayes_opt)来进行模型参数调优。
模型融合策略
常用模型融合的策略有两种,分别是Voting融合与Stacking融合。在Voting过程中,我们只需要对不同模型对测试集的预测结果进行加权汇总即可,而Stacking则相对复杂,需要借助此前不同模型的验证集预测结果和测试集预测结果再次进行模型训练,以验证集预测结果为训练集、训练集标签为标签构建新的训练集,在此模型上进行训练,然后以测试集预测结果作为新的预测集,并在新预测集上进行预测。
Voting:均值融合(多组预测结果求均值)
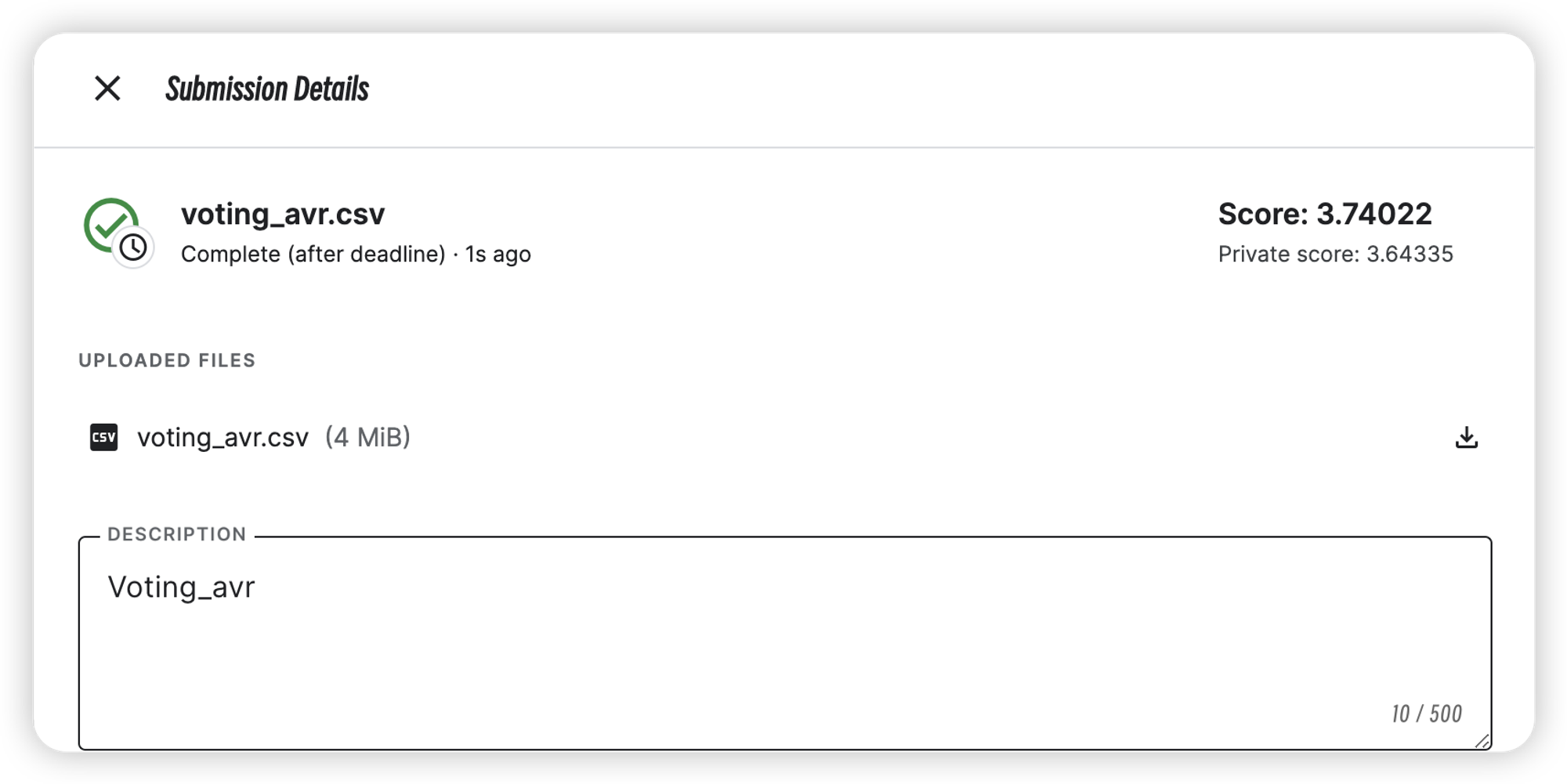
能够发现,简单的均值融合并不能有效果上的提升
Voting:加权融合(根据某种方式赋予不同预测结构不同权重而后进行求和)
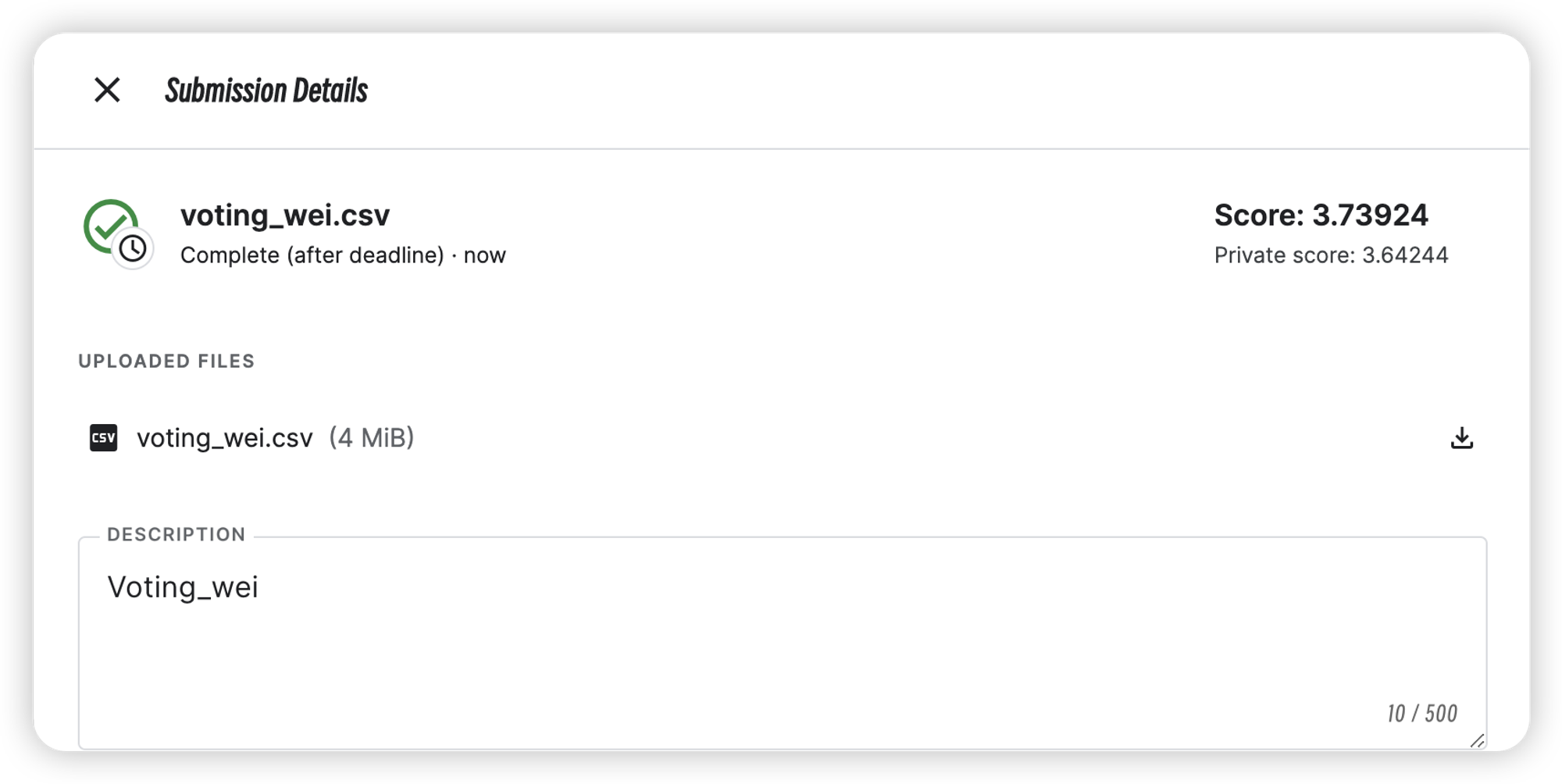
发现结果略微有所改善,但实际结果仍然不如单模型结果,此处预测极有可能是因额外i标签中存在异常值导致。接下来继续尝试Stacking融合。
Stacking 融合
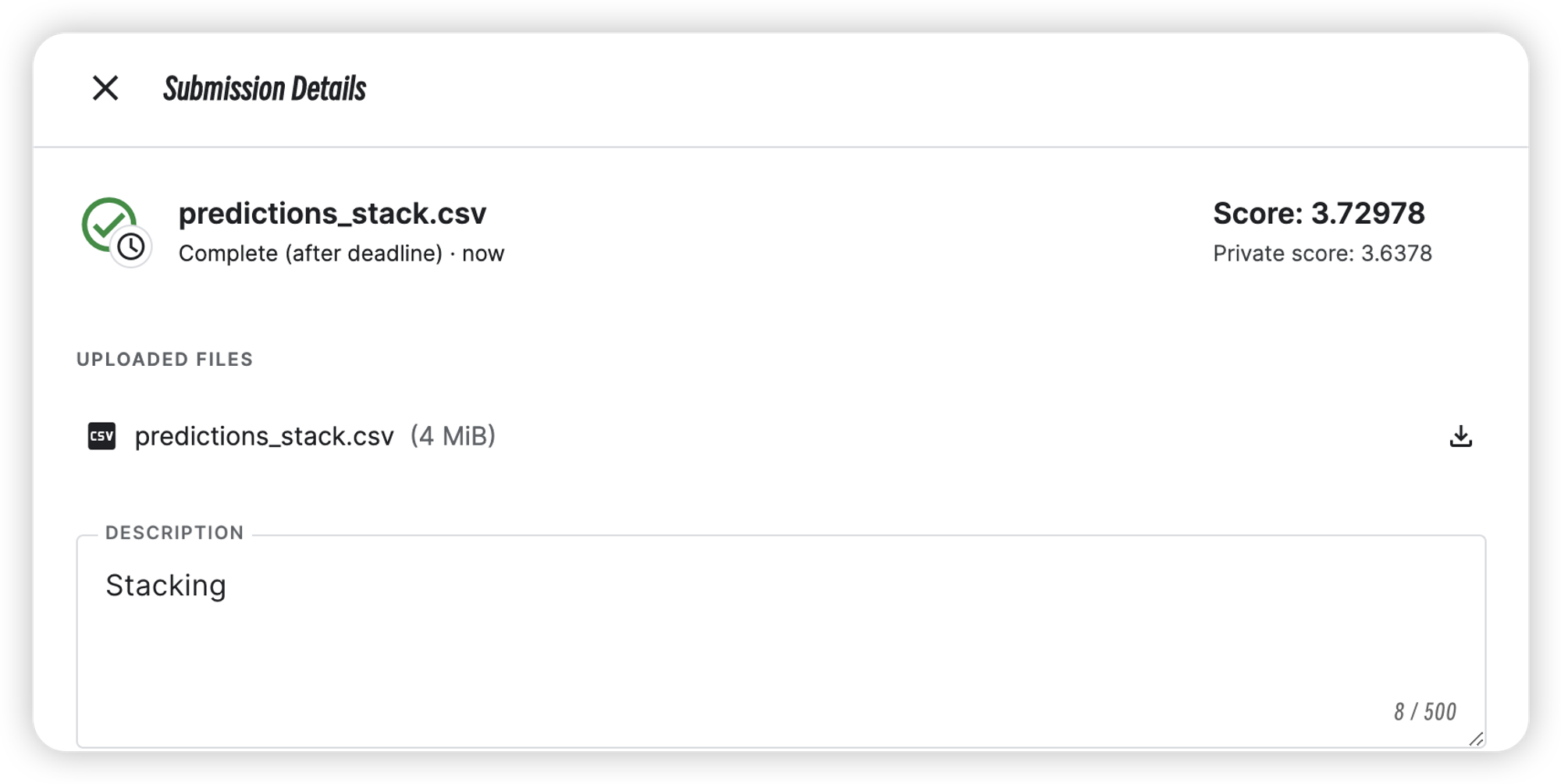
特征优化与模型融合优化
优化思路梳理
整体优化思路
首先,先来看特征优化思路。在此前的建模过程中,我们曾不止一次的对特征进行了处理,首先是在数据聚合时(以card_id进行聚合),为了尽可能提取更多的交易数据信息与商户信息带入进行模型,我们围绕交易数据表和商户数据表进行了工程化批量特征衍生,彼时信息提取流程如下:
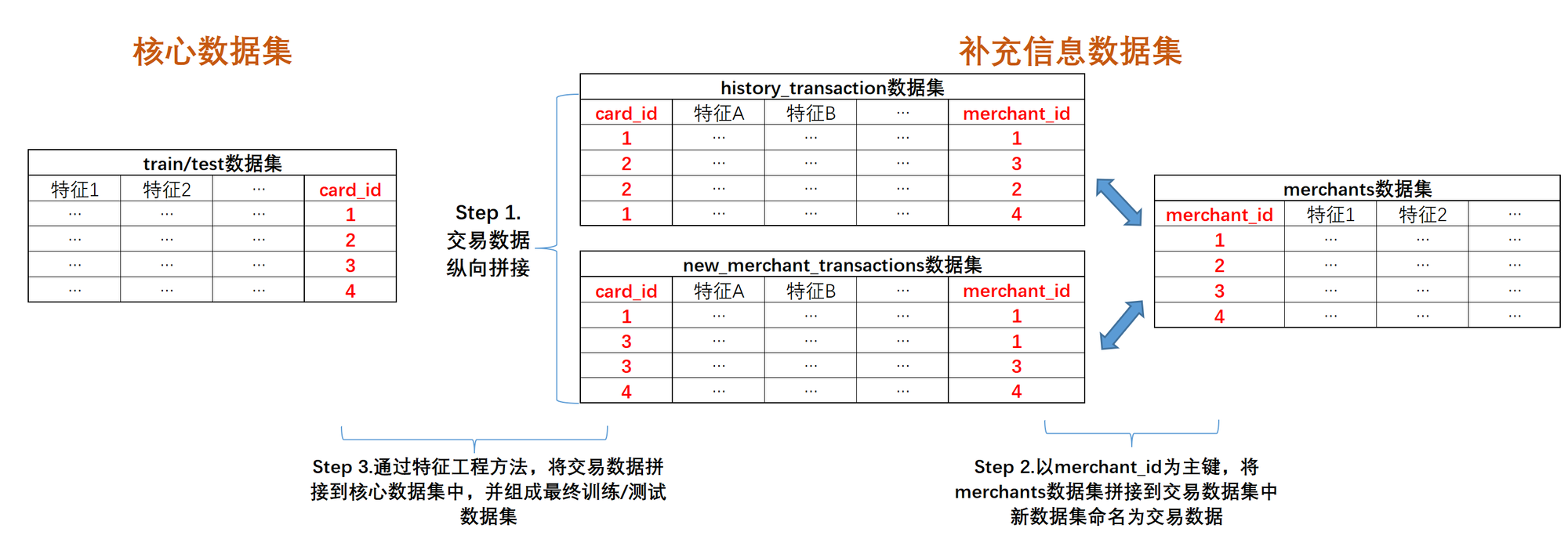
具体的特征衍生方案是采用了交叉组合特征创建与业务统计特征创建两种方案:
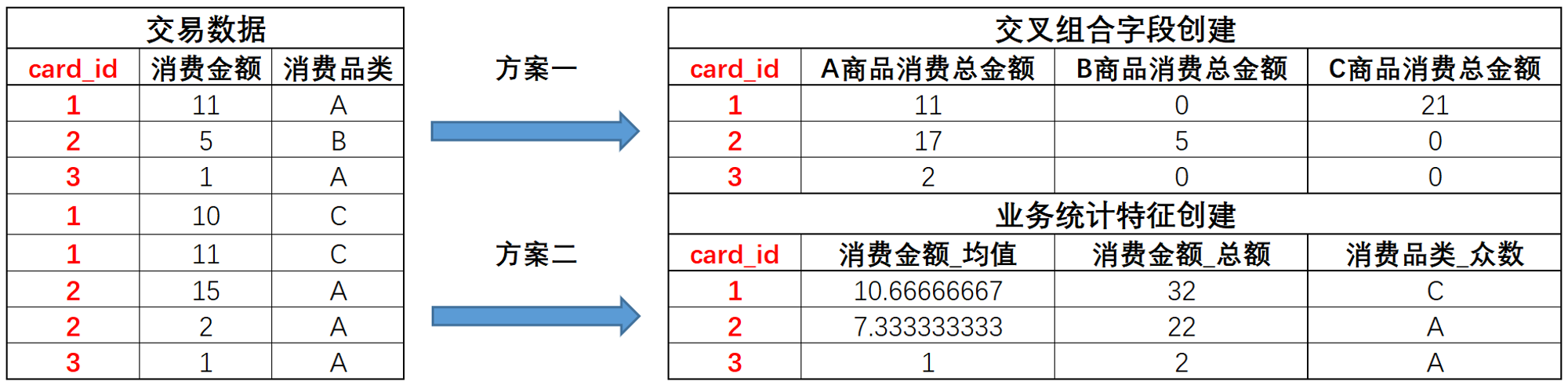
总体来看,特征优化需要结合数据集当前的实际情况来制定,在已有批量衍生的特征及NLP特征的基础上,针对上述数据集,还可以有以下几点优化方向:
-
用户行为特征
- 首先,我们注意到,每一笔信用卡的交易记录都有交易时间,而对于时间字段和文本字段,普通的批量创建特征的方法都是无法较好的挖掘其全部信息的,因此我们需要围绕交易字段中的交易时间进行额外的特征衍生。此处我们可以考虑构造一些用于描述用户行为习惯的特征(经过反复验证,用户行为特征是最为有效的提高预测结果的特征类),包括最近一次交易与首次交易的时间差、信用卡激活日期与首次交易的时间差、用户两次交易平均时间间隔、按照不同交易地点/商品品类进行聚合(并统计均值、方差等统计量)。
- 此外,我们也知道越是接近当前时间点的用户行为越有价值,因此我们还需要重点关注用户最近两个月(实际时间跨度可以自行决定)的行为特征,以两个月为跨度,进一步统计该时间周期内用户的上述交易行为特点,并带入模型进行训练。
-
二阶交叉特征
- 在此前的特征衍生过程中,我们曾进行了交叉特征衍生,但只是进行了一阶交叉衍生,例如交易额在不同商品上的汇总,但实际上还可以进一步构造二阶衍生,例如交易额在不同商品组合上的汇总。通常来说更高阶的衍生会导致特征矩阵变得更加稀疏,并且由于每一阶的衍生都会创造大量特征,因此更高阶的衍生往往也会造成维度爆炸,因此高阶交叉特征衍生需要谨慎。不过正如此前我们考虑的,由于用户行为特征对模型结果有更大的影响,因此我们可以单独围绕用户行为数据进行二阶交叉特征衍生,并在后续建模前进行特征筛选。
-
异常值识别特征
-
训练数据集的标签中存在少量极端异常值的情况
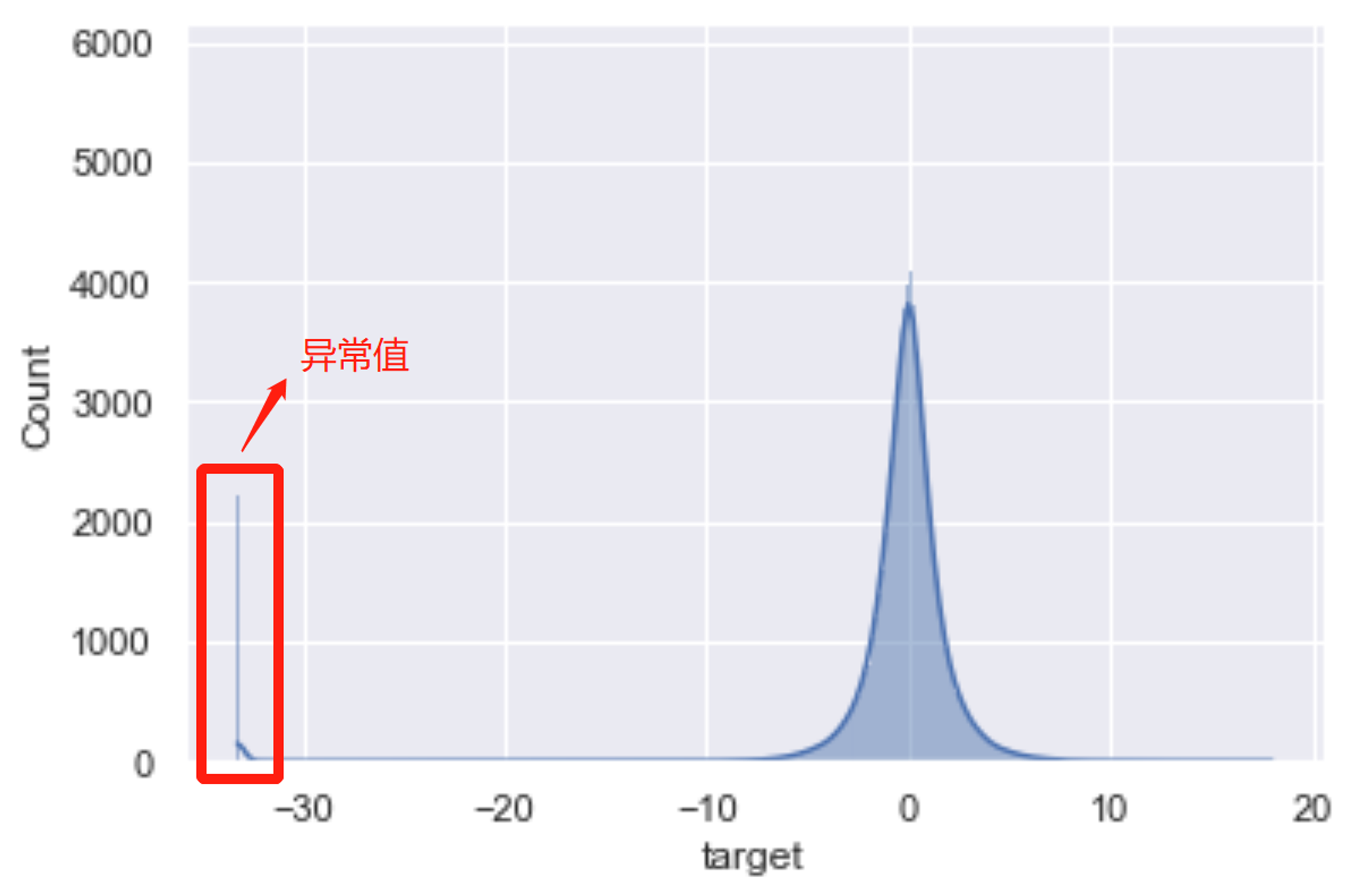
-
而若我们更进一步就此前的建模结果展开分析的话,我们会发现,此前的模型误差大多数都源于对异常值用户(card_id)的预测结果。而根据讨论知道,实际上用户评分是通过某套公式人工计算得出的,因此这些异常值极有可能是某类特殊用户的标记,因此我们不妨在实际建模过程中进行两阶段建模,即先预测每个输入样本是否是异常样本,并根据分类预测结果进行后续的回归建模,基本流程如下:
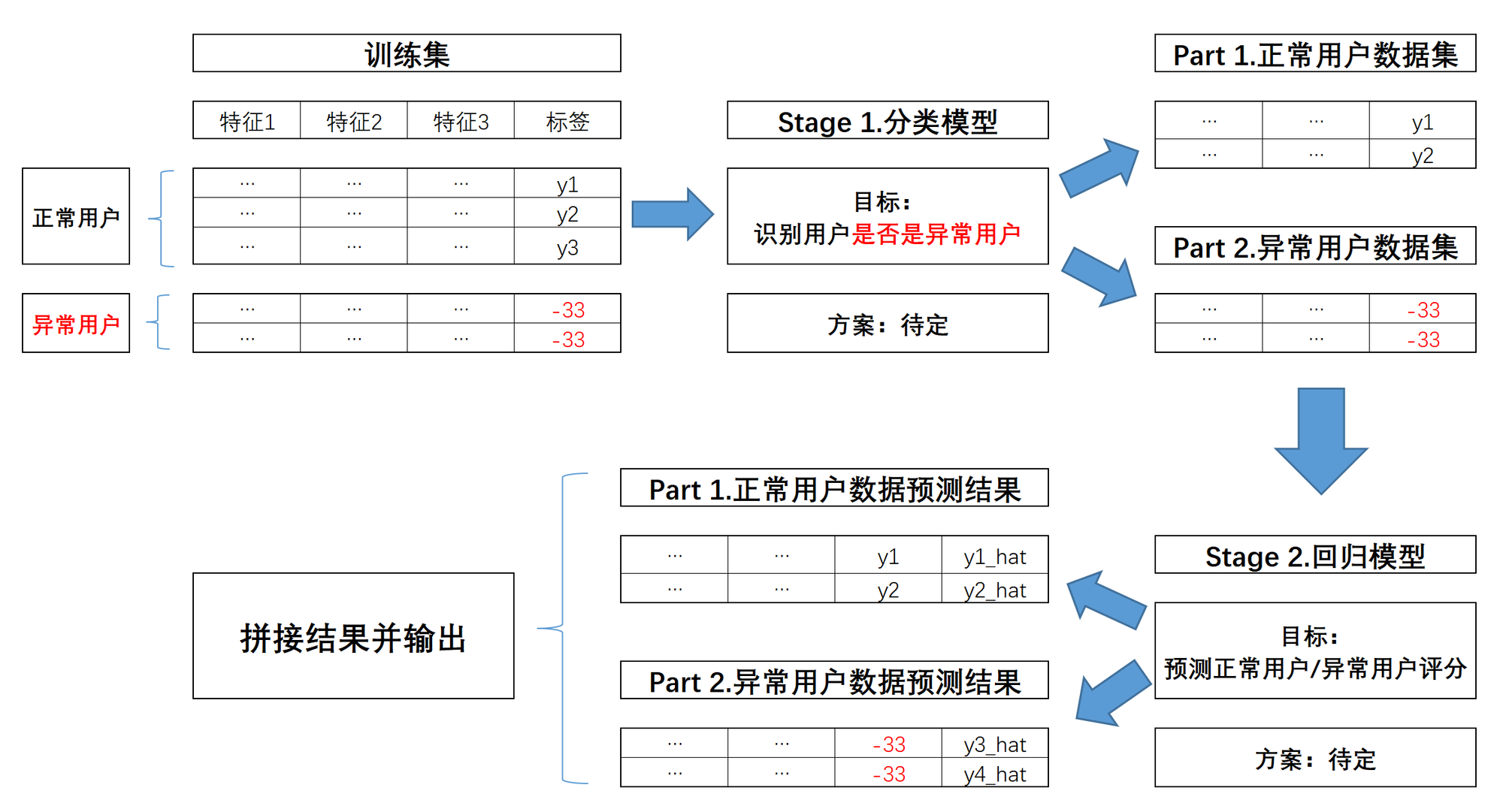
-
而为了保证后续两阶段建模时第一阶段的分类模型能够更加准确的识别异常用户,我们需要创建一些基于异常用户的特征聚合字段,例如异常用户平均消费次数、消费金额等。
-
模型优化思路
-
新增CatBoost模型
- CatBoost是由俄罗斯搜索引擎Yandex在2017年7月开源的一个GBM算法,自开源之日起,CatBoost就因为其强大的效果与极快的执行效率广受算法工程人员青睐。在诸多CatBoost的算法优势中,最引人关注的当属该模型能够自主采用独热编码和平均编码的混合策略来处理类别特征,也就是说CatBoost将一些经过实践验证的、普遍有效的特征工程方法融入了实际模型训练过程;此外,CatBoost还提出了一种全新的梯度提升的机制,能够非常好的在经验风险和结构风险中做出权衡(即能够很好的提升精度、同时又能够避免过拟合问题)。
-
二阶段建模
-
而从模型训练流程角度出发,则可以考虑进行二阶段建模,基本流程如下:
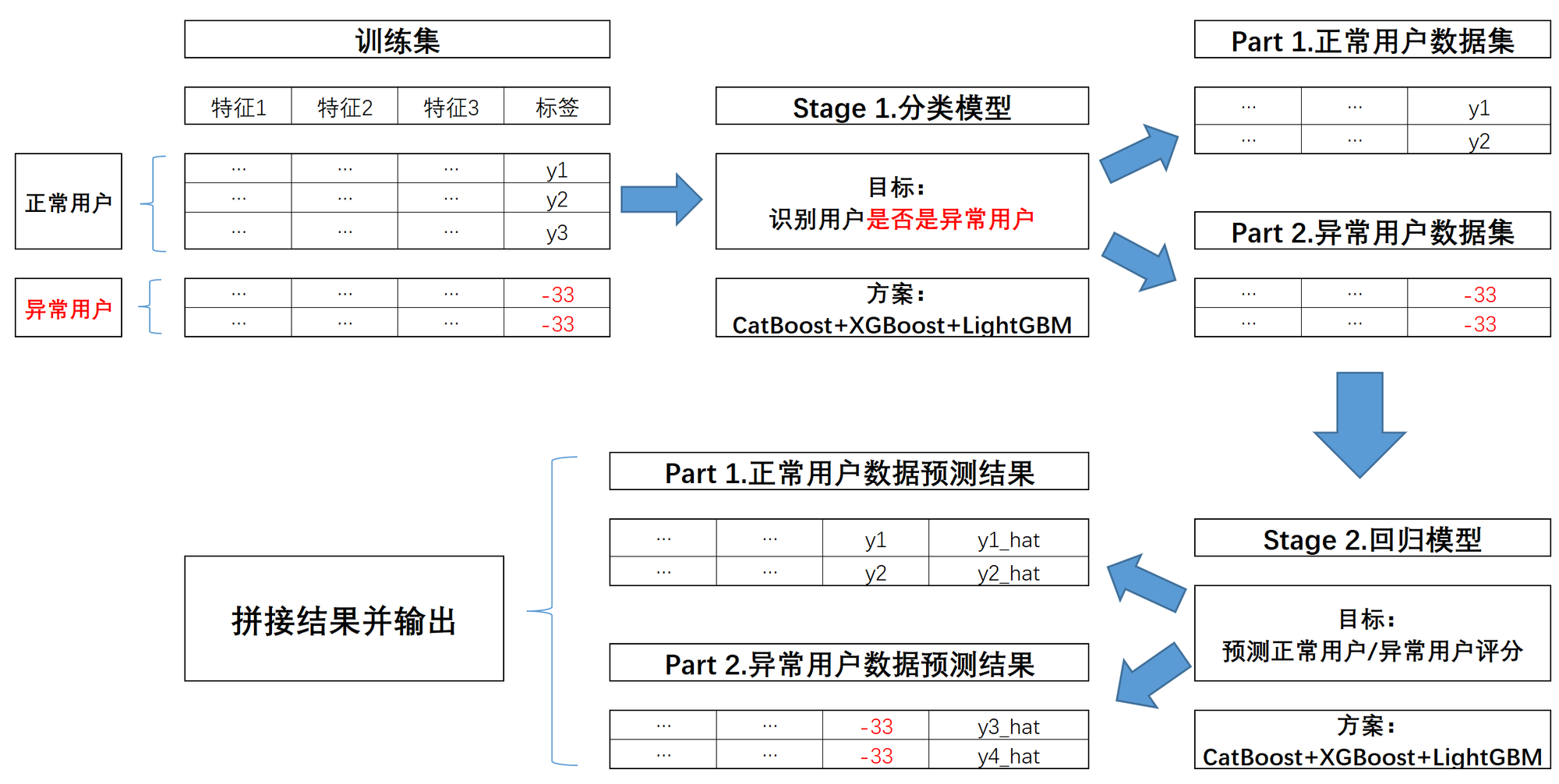
-
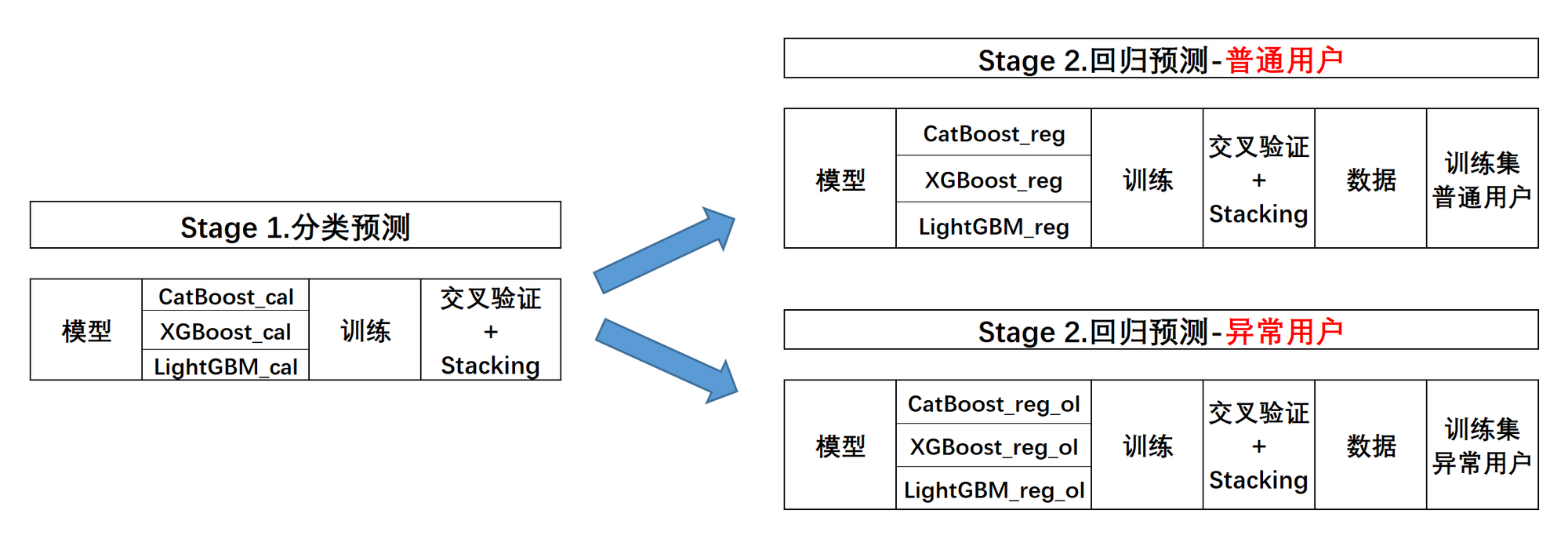
并且,需要注意的是,在实际二阶段建模过程时,我们需要在每个建模阶段都进行交叉验证与模型融合,才能最大化提升模型效果。也就是说我们需要训练三组模型(以及对应进行三次模型融合),来完成分类预测问题、普通用户回归预测问题和异常用户回归预测问题。三轮建模关系如下:
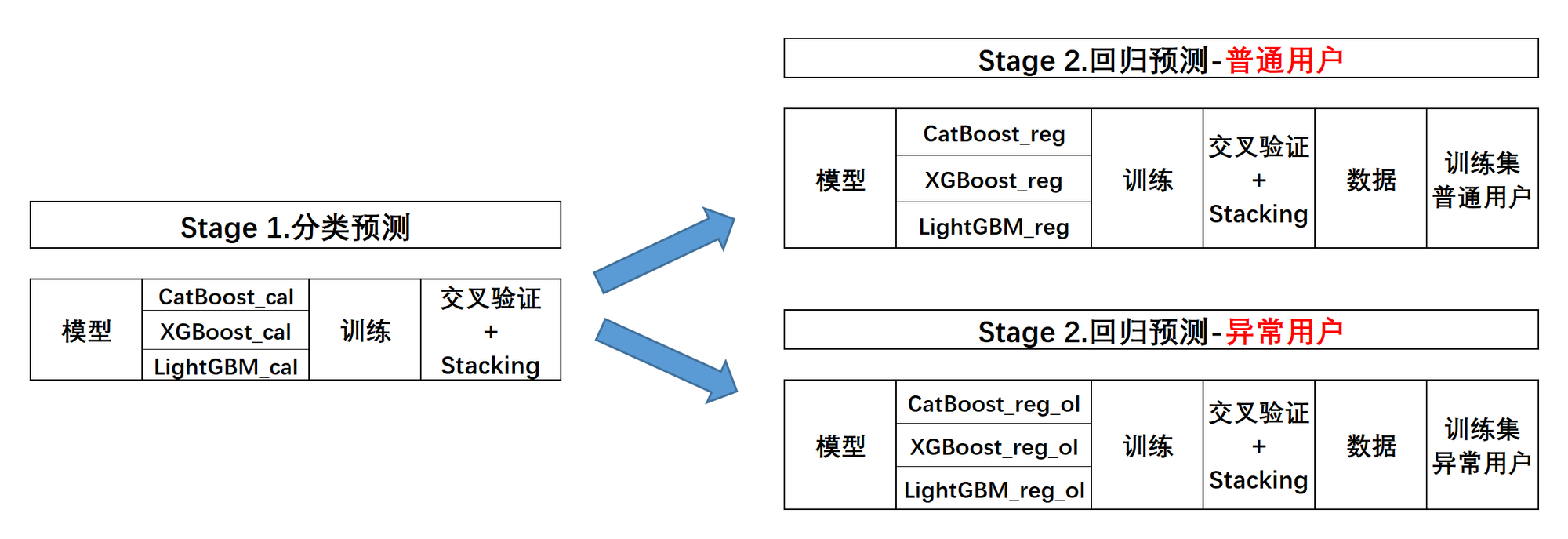
-
不难发现,整体建模与融合过程都将变得更加复杂。不过这也是更加贴近真实状态的一种情况,很多时候算法和融合过程都只是元素,如何构建一个更加精准、高效的训练流程,才是进阶的算法工程人员更需要考虑的问题。
-
数据预处理与特征优化
数据预处理
- 此处由于需要进行特征优化,因此数据处理工作需要从头开始执行。首先需要进行数据读取,并进行缺失值处理
- 然后需要进行时间字段的更细粒度的呈现
特征优化部分
- 在执行完数据清洗与时间字段的处理之后,接下来我们需要开始执行特征优化。根据此前介绍的思路,首先我们需要进行基础行为特征字段衍生
- 然后,需要进一步考虑最近两个月的用户行为特征
- 以及进一步进行二阶交叉特征衍生
- 将上述衍生特征进行合并
- 并在此基础上补充部分简单四折运算后的衍生特征
特征筛选
在创建完全部特征后即可进行特征筛选了。此处我们考虑手动进行特征筛选,排除部分过于稀疏的特征后即可将数据保存在本地。
LightGBM + XGBoost + CatBoost两阶段建模
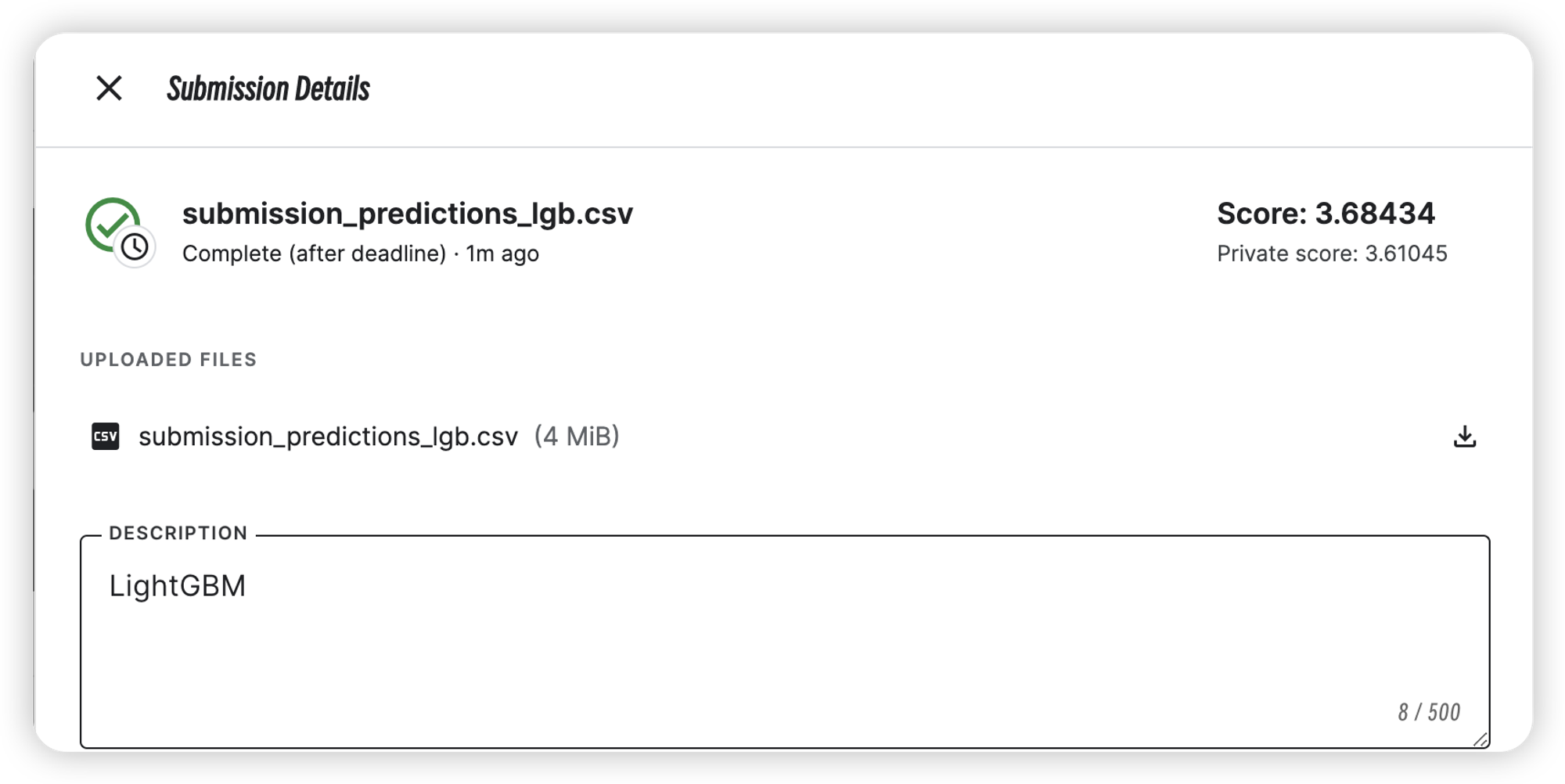
LightGBM模型训练
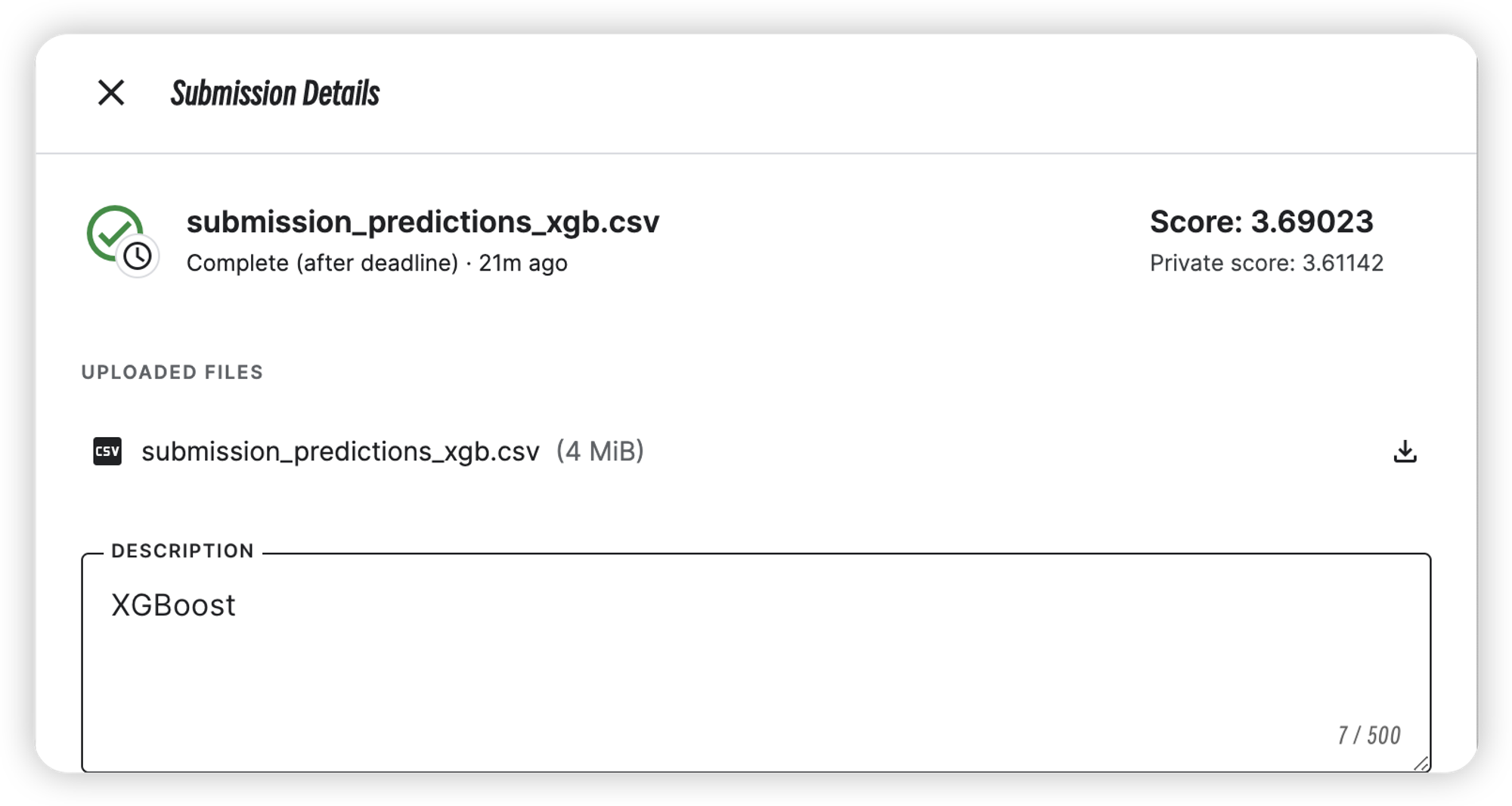
xgboost模型训练
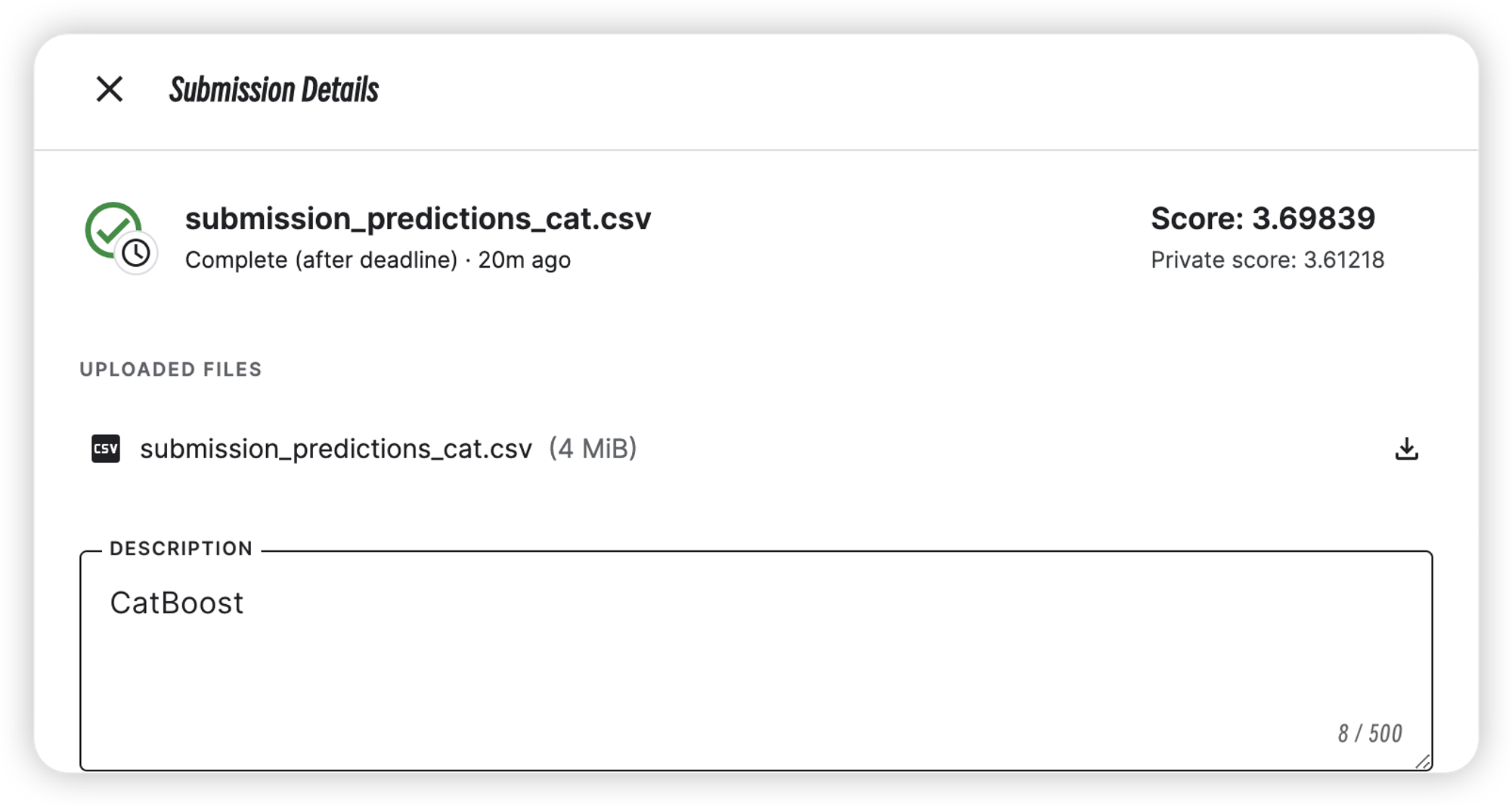
CatBoost
融合阶段
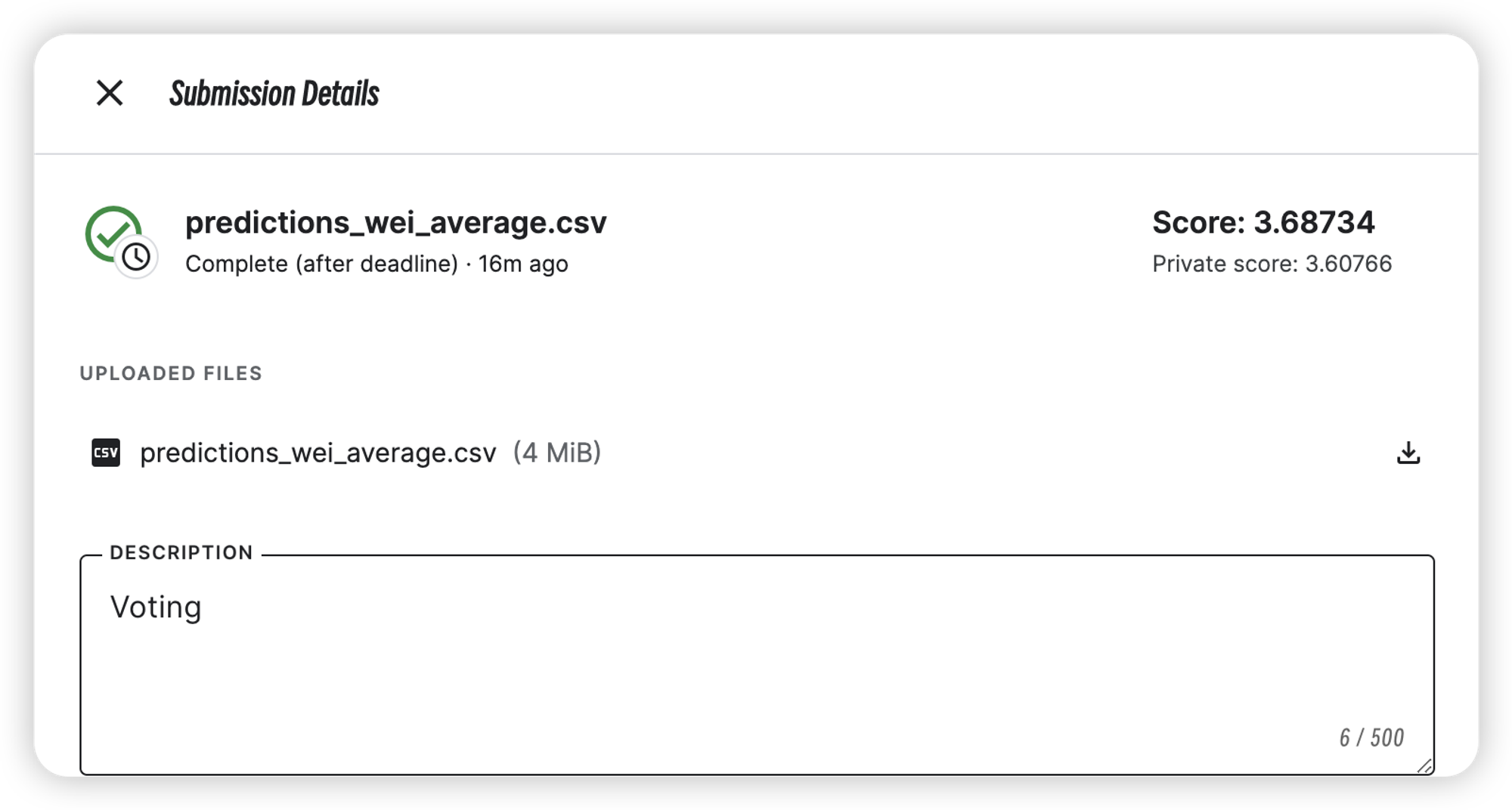
加权融合
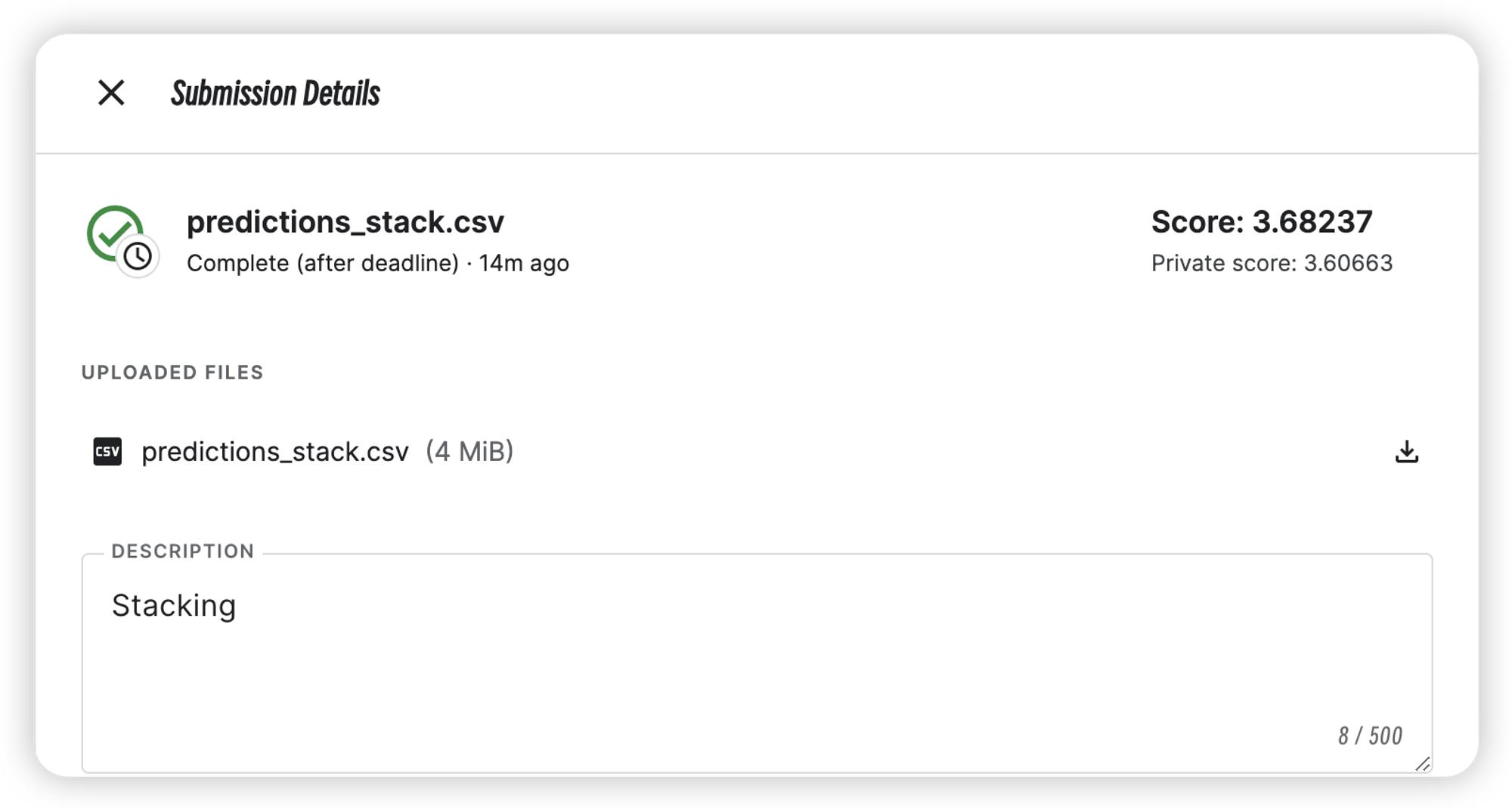
Stacking融合
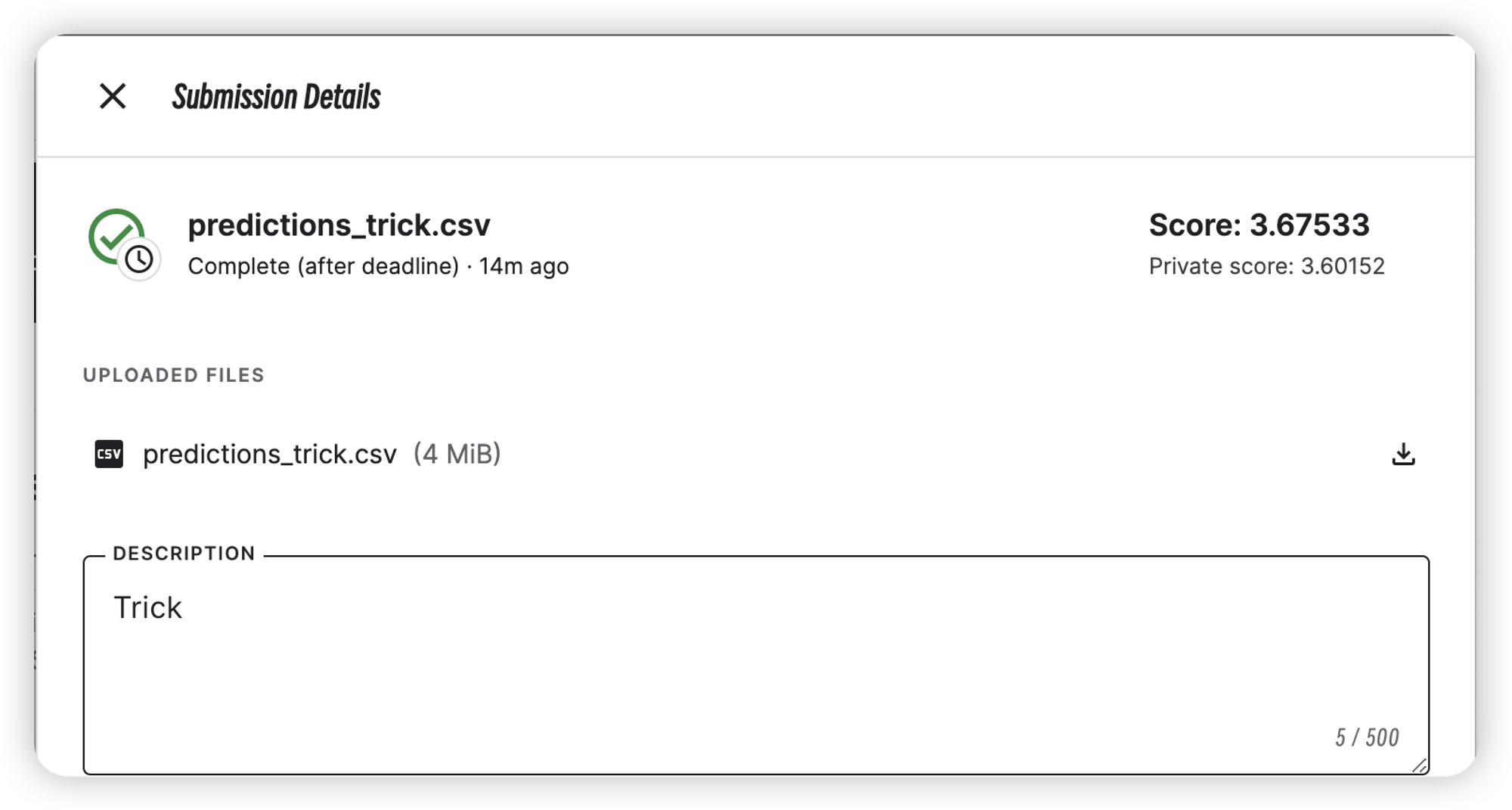
Trick融合
Trick & Stacking
结论
提交结果
第一阶段
| 模型 | Private Score | Public Score |
|---|---|---|
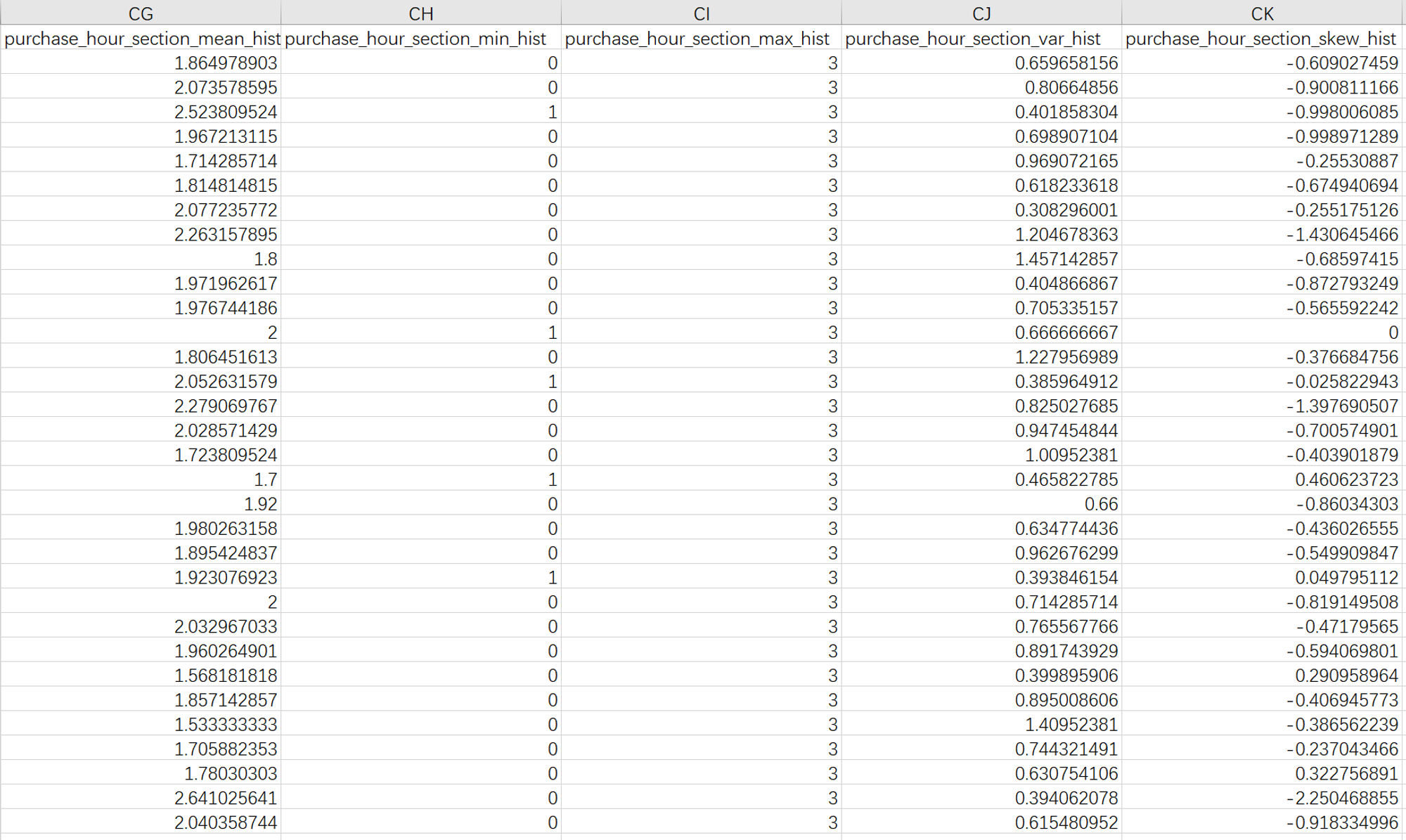
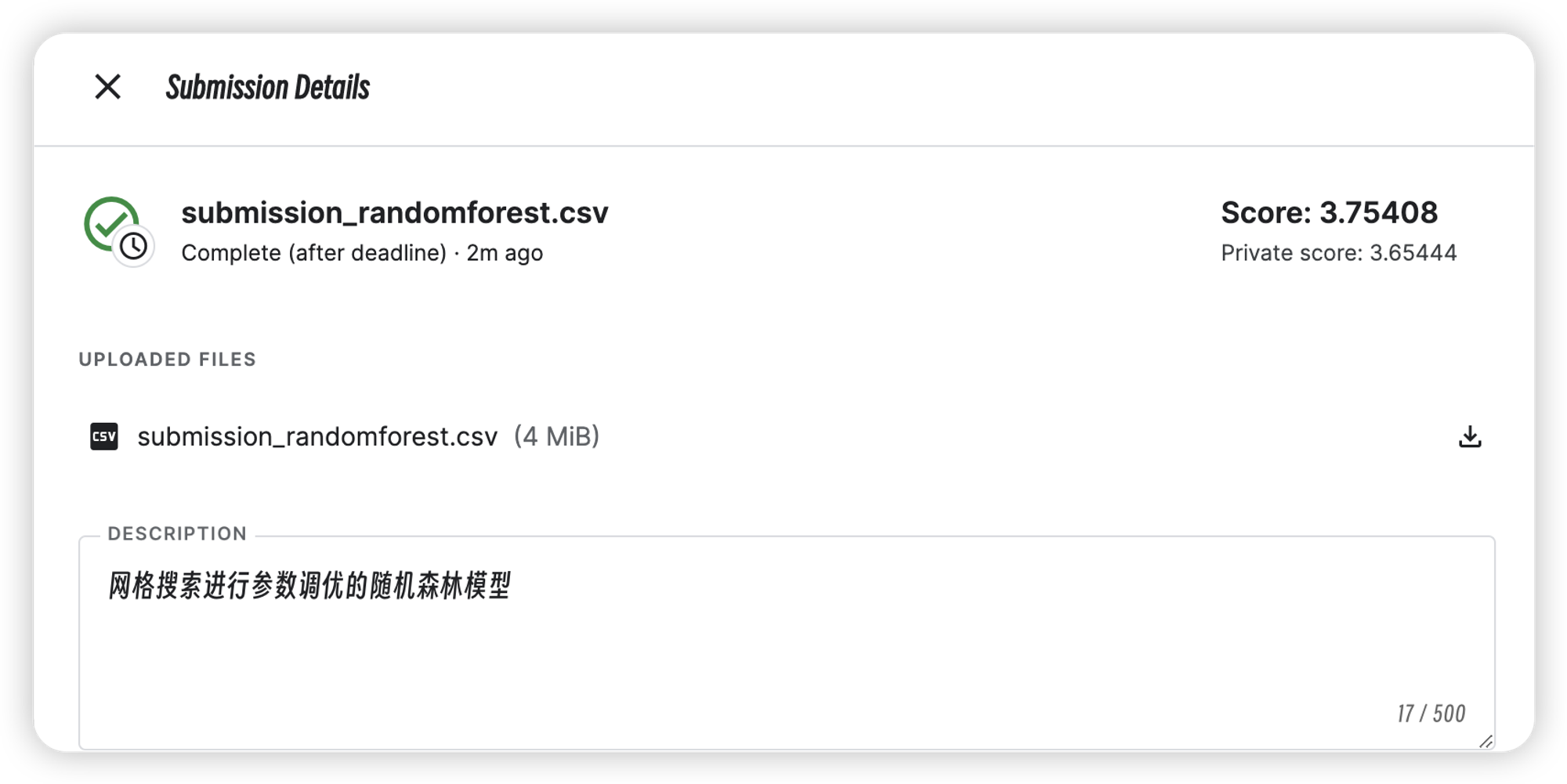
| randomforest | 3.65444 | 3.75408 |
| randomforest+validation | 3.65173 | 3.74954 |
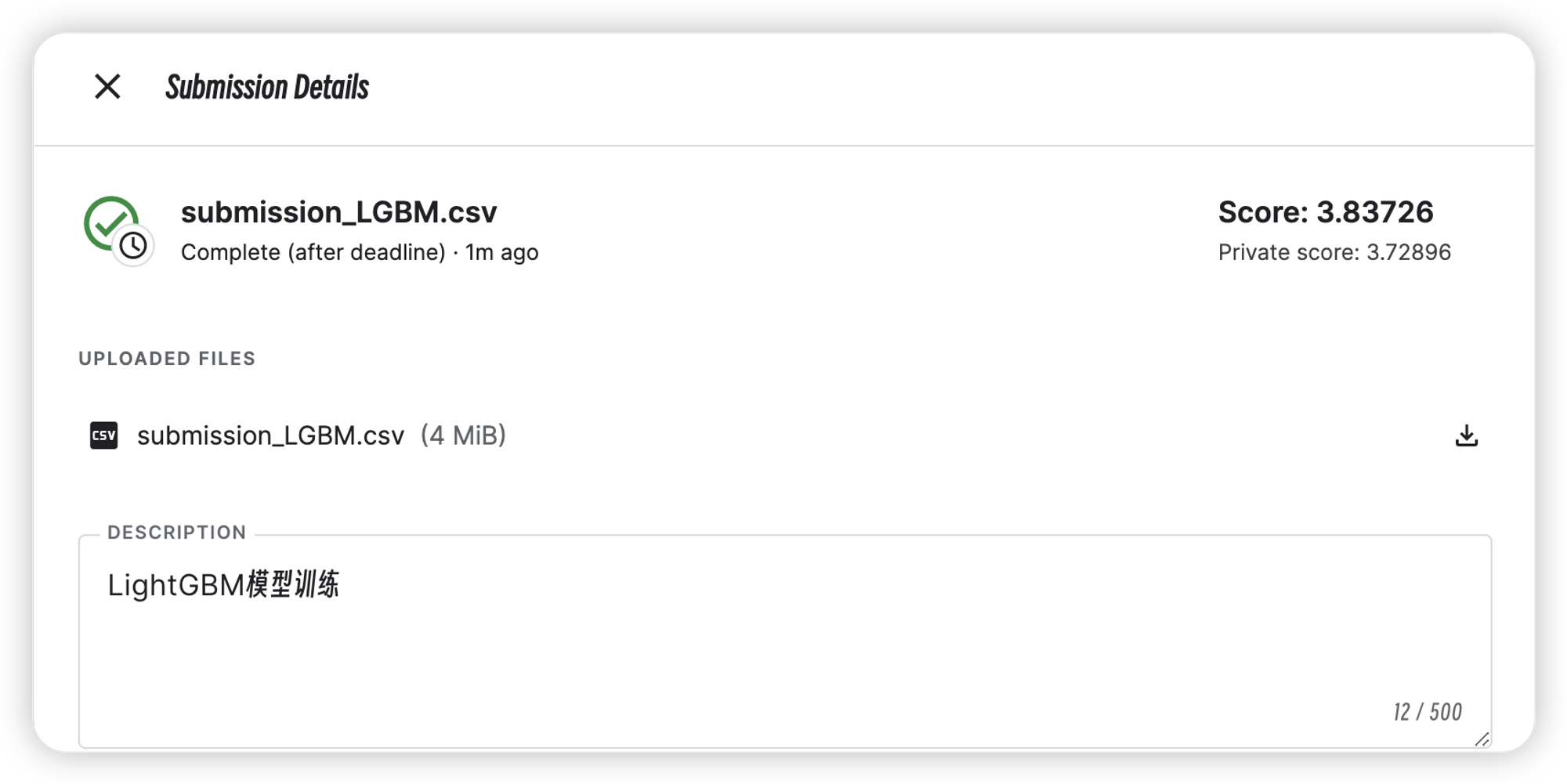
| LightGBM | 3.72896 | 3.83726 |
| LightGBM+validation | 3.64807 | 3.74323 |
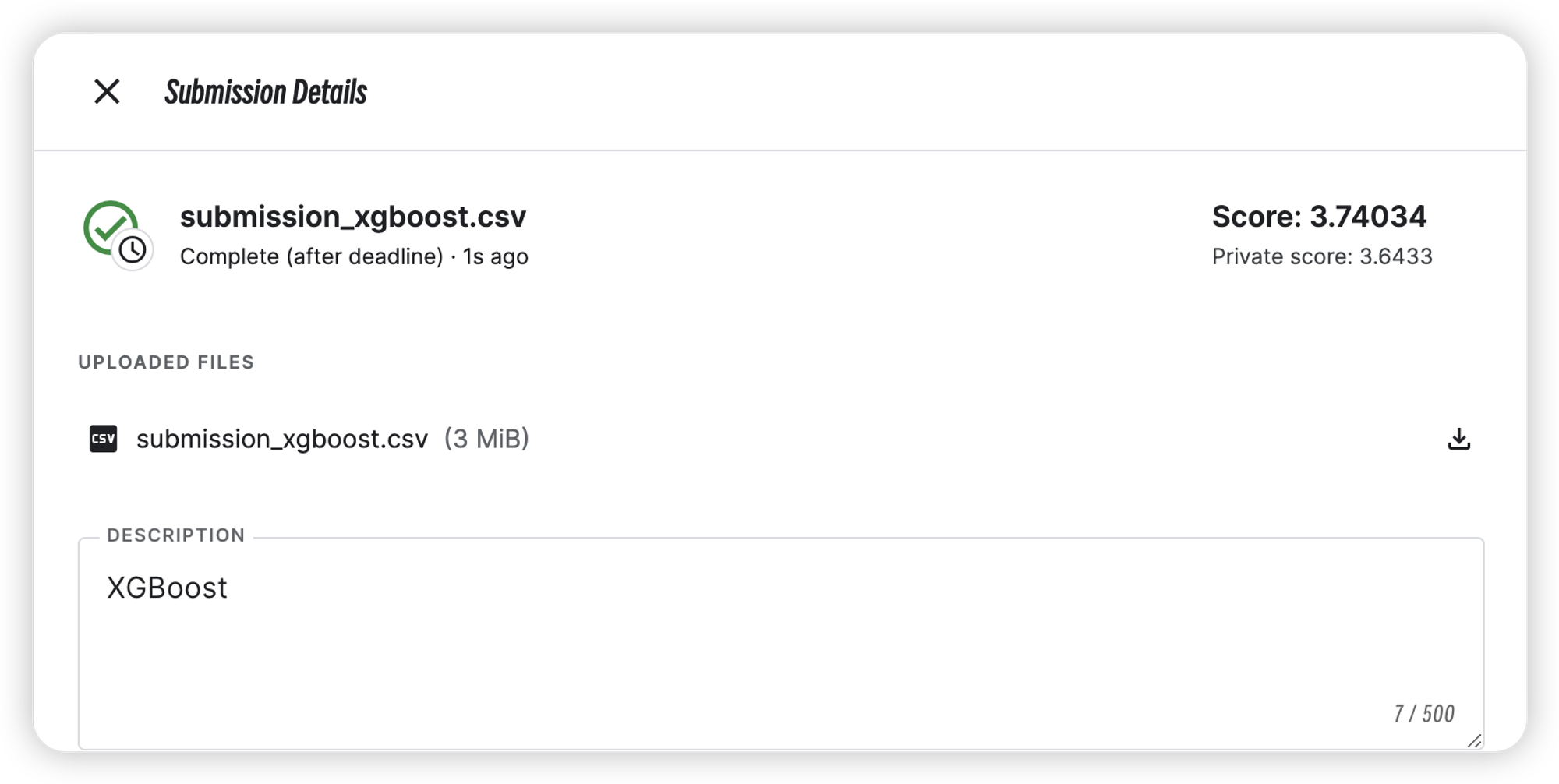
| XGBoost | 3.6433 | 3.74034 |
| Voting_avr | 3.64335 | 3.74022 |
| Voting_wei | 3.64244 | 3.73924 |
| Stacking | 3.6378 | 3.72978 |
第二阶段
| 模型 | Private Score | Public Score |
|---|---|---|
| LightGBM | 3.61045 | 3.68434 |
| XGBoost | 3.61142 | 3.69023 |
| CatBoost | 3.61218 | 3.69839 |
| Voting | 3.60766 | 3.68734 |
| Stacking | 3.60663 | 3.68237 |
| Trick | 3.60152 | 3.67533 |
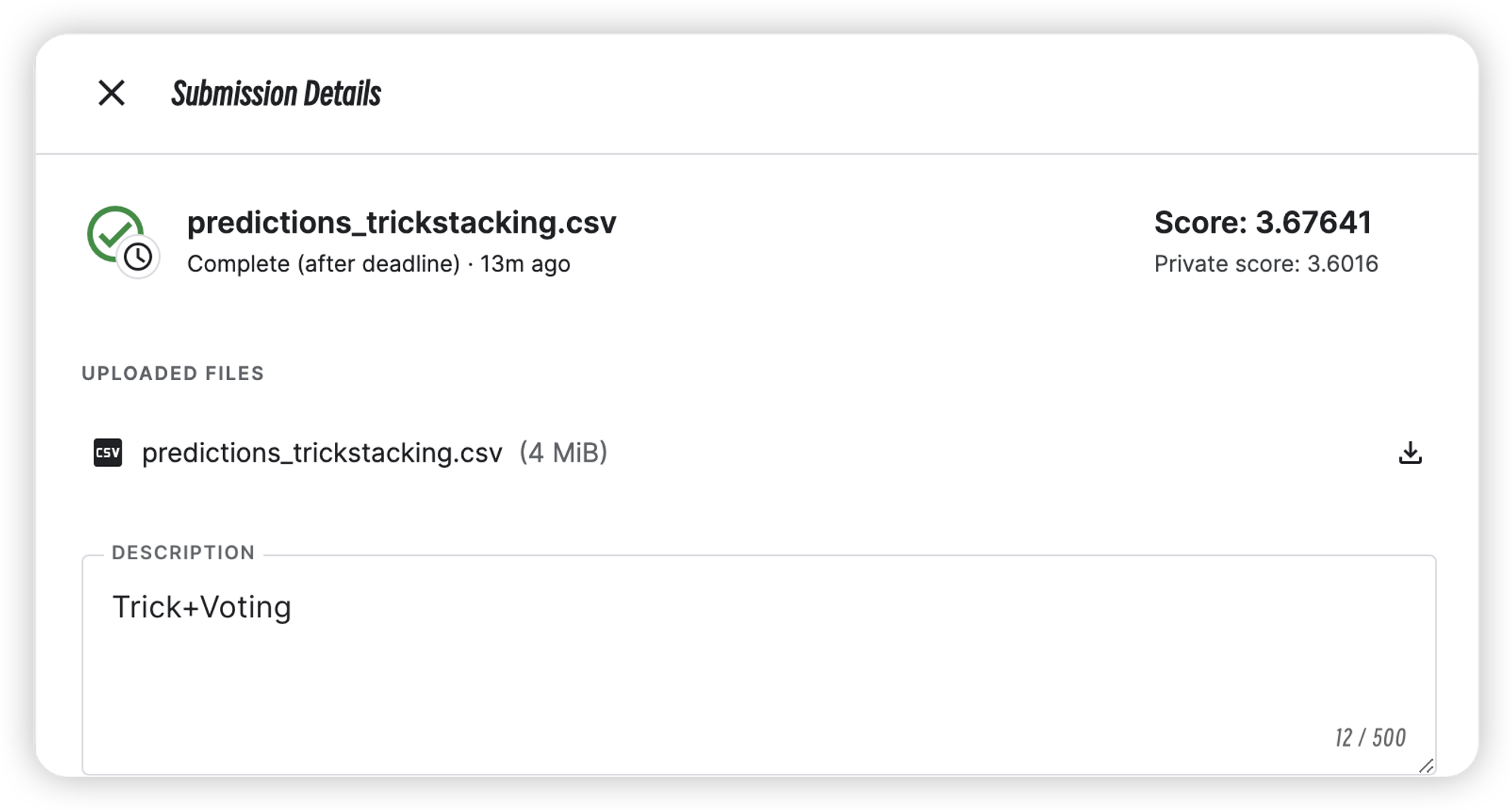
| Trick+Voting | 3.6016 | 3.67641 |
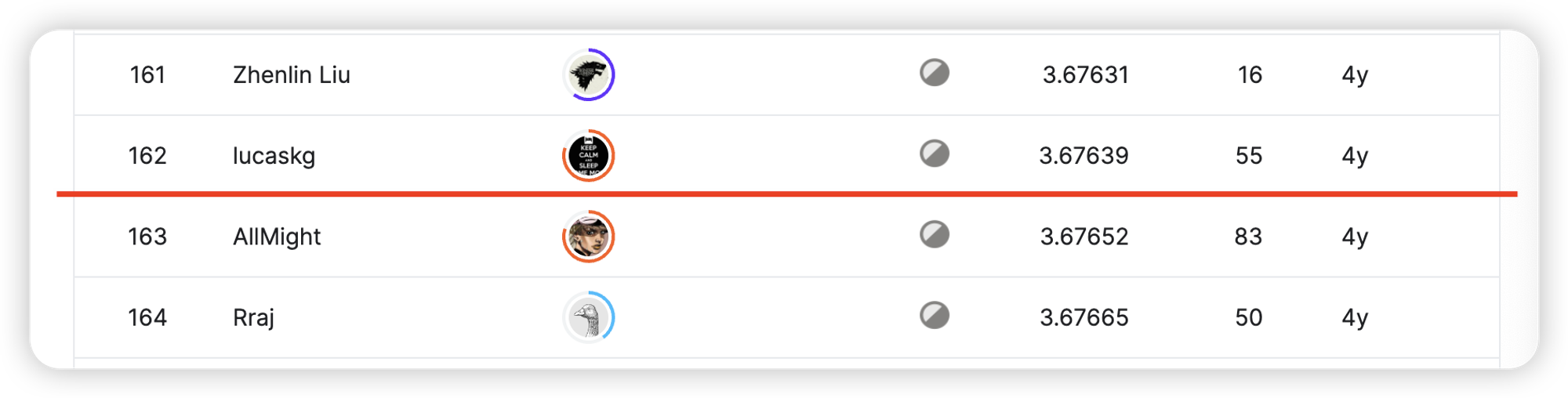
最终结果(截止 2022/12/6 12:00)
私榜: 23 / 4111 = 0.00559475
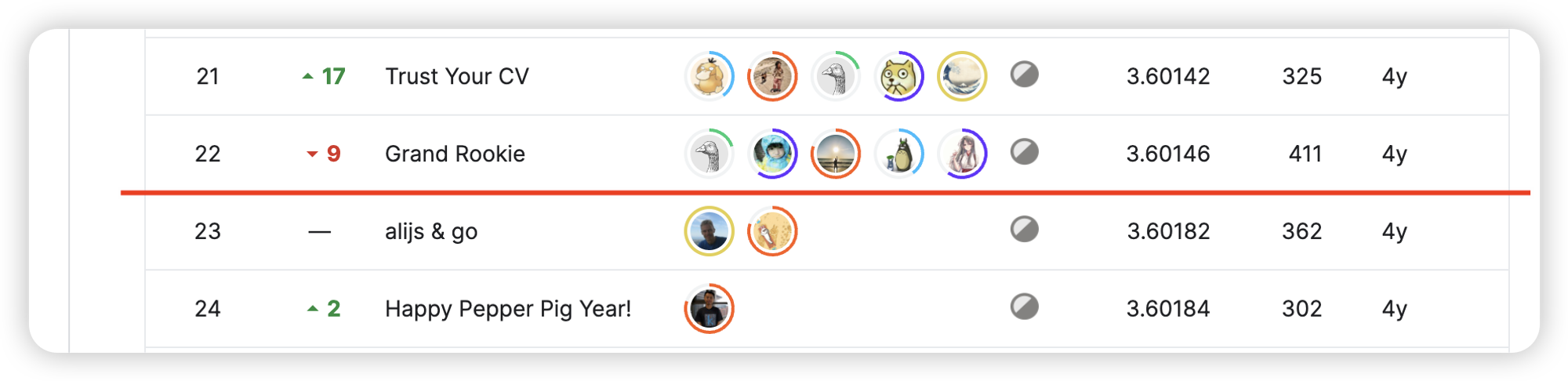
公榜: 163 / 4111 = 0.03964972