
数据库原理:作业 04
实验四:图书管理系统案例分析
一、相关知识点
- java基础知识
- Eclipse环境的基本配置
- 数据库基础知识
- JDBC基本概念
- java连接数据库的方式
- JDBC简单查询
二、实验目的:
分析图书管理系统的组成部分,理解其数据库设计和程序模块;在教师指导下阅读各模块的程序,理解持久数据、内存数据、感官数据的基本转换方式。
理解Java连接数据库的基本概念。理解JDBC的四种驱动程序,掌握纯java驱动。理解Statement对象和ResultSet对象。
三、实验内容:
1、 图书管理系统数据库实施:参考讲义中的实施过程。
A、用表格形式编写数据库表的设计,表格格式如下。
- beanbook
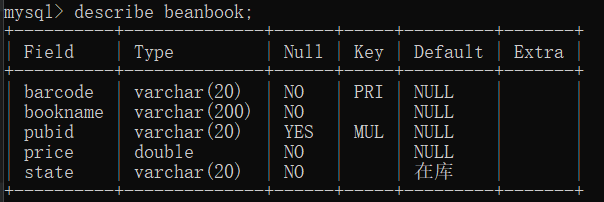
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| barcode | 条形码 | varchar(20) | 否 | 主码 |
| bookname | 书名 | varchar(200) | 否 | |
| pubid | 出版社ID | varchar(20) | 是 | 外码,默认为空,拥有名为fk_pubid_idx的普通索引,拥有名为fk_pubid的约束,不允许beanpublisher表删除或更新相应的pubid记录 |
| price | 售价 | double | 否 | |
| state | 库存状态 | varchar(20) | 否 | 默认为'在库' |
- beanbooklendrecord
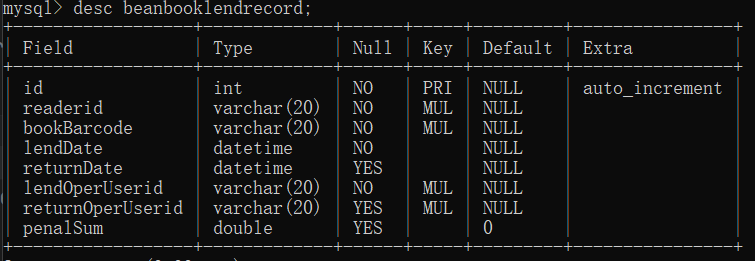
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| id | ID | int | 否 | 主码,添加了AUTO_INCREMENT,每次插入新记录时会自动地创建主键字段的值 |
| readerid | 读者ID | varchar(20) | 否 | 外码,拥有名为fk_reader_idx的普通索引,拥有名为fk_reader的约束,不允许beanreader表删除或更新相应的readerid记录 |
| bookBarcode | 书的条码 | varchar(20) | 否 | 外码,拥有名为fk_book_idx的普通索引,拥有名为fk_book的约束,不允许beanbook表删除或更新相应的bookBarcode记录 |
| lendDate | 借书日期 | datetime | 否 | |
| returnDate | 归还日期 | datetime | 是 | 默认为空 |
| lendOperUserid | 处理借出操作的用户ID | varchar(20) | 否 | 外码,拥有名为fk_lendOper_idx的普通索引,拥有名为fk_lendOper的约束,不允许beansystemuser表删除或更新相应的userid记录 |
| returnOperUserid | 处理归还操作的用户ID | varchar(20) | 是 | 外码,默认为空,拥有名为fk_returnOper_idx的普通索引,拥有名为fk_returnOper的约束,不允许beansystemuser表删除或更新相应的userid记录 |
| penalSum | 罚款 | double | 是 | 默认为0 |
- beanpublisher
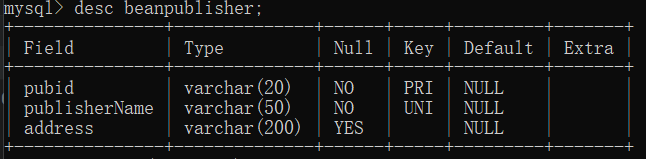
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| pubid | 出版社ID | varchar(20) | 否 | 主码 |
| publisherName | 出版社名 | varchar(50) | 否 | 拥有名为publisherName_UNIQUE 的唯一约束 |
| address | 地址 | varchar(200) | 是 | 默认为空 |
- beanreader
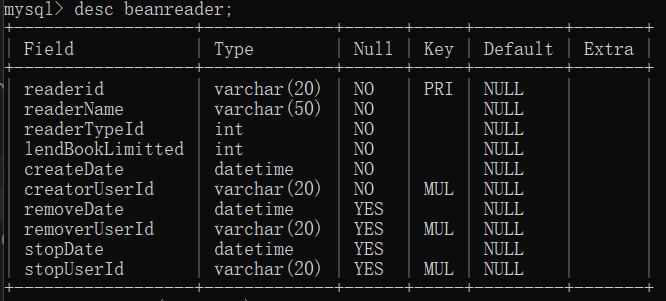
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| readerid | 读者ID | varchar(20) | 否 | 主码 |
| readerName | 读者名 | varchar(50) | 否 | |
| readerTypeId | 读者类型ID | int | 否 | |
| lendBookLimitted | 借书限制 | int | 否 | |
| createDate | 创建时间 | datetime | 否 | |
| creatorUserId | 创建读者的用户的ID | varchar(20) | 否 | 外码,默认为空,拥有名为fk_stopper_idx的普通索引,拥有名为fk_stopper的约束,不允许beansystemuser表删除或更新相应的userid记录 |
| removeDate | 删除时间 | datetime | 是 | 默认为空 |
| removerUserId | 删除读者的用户的ID | varchar(20) | 是 | 外码,默认为空,拥有名为fk_remover_idx的普通索引,拥有名为fk_remover的约束,不允许beansystemuser表删除或更新相应的userid记录 |
| stopDate | 封停时间 | datetime | 是 | 默认为空 |
| stopUserId | 封停读者的用户的ID | varchar(20) | 是 | 外码,默认为空,拥有名为fk_stopper_idx的普通索引,拥有名为fk_stopper的约束,不允许beansystemuser表删除或更新相应的userid记录 |
- beanreadertype
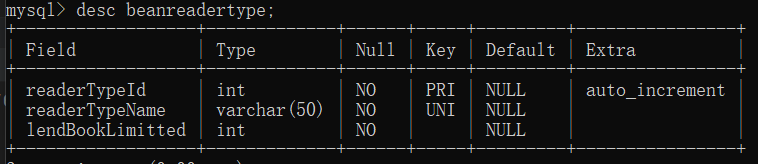
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| readerTypeId | 读者类型ID | int | 否 | 主码,添加了AUTO_INCREMENT,每次插入新记录时,会自动地创建主键字段的值 |
| readerTypeName | 读者类型名 | varchar(50) | 否 | 拥有名为readerTypeName_UNIQUE的唯一约束 |
| lendBookLimitted | 借书限制 | int | 否 |
- beansystemuser
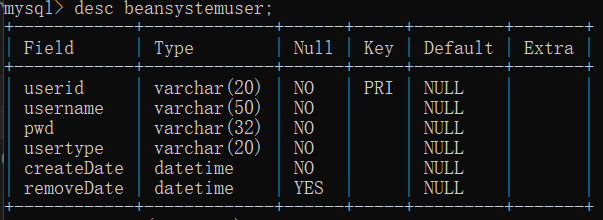
| 字段名 | 中文名称 | 数据类型 | 能否为空 | 说明 |
|---|---|---|---|---|
| userid | 用户ID | varchar(20) | 否 | 主码 |
| username | 用户名 | varchar(50) | 否 | |
| pwd | 密码 | varchar(32) | 否 | |
| usertype | 用户类型 | varchar(20) | 否 | |
| createDate | 创建时间 | datetime | 否 | |
| removeDate | 删除时间 | datetime | 是 | 默认为空 |
B、通过脚本默认加入的数据在哪张表?
beansystemuser
2、JDK、Eclipse安装和配置:参考讲义中的安装配置过程
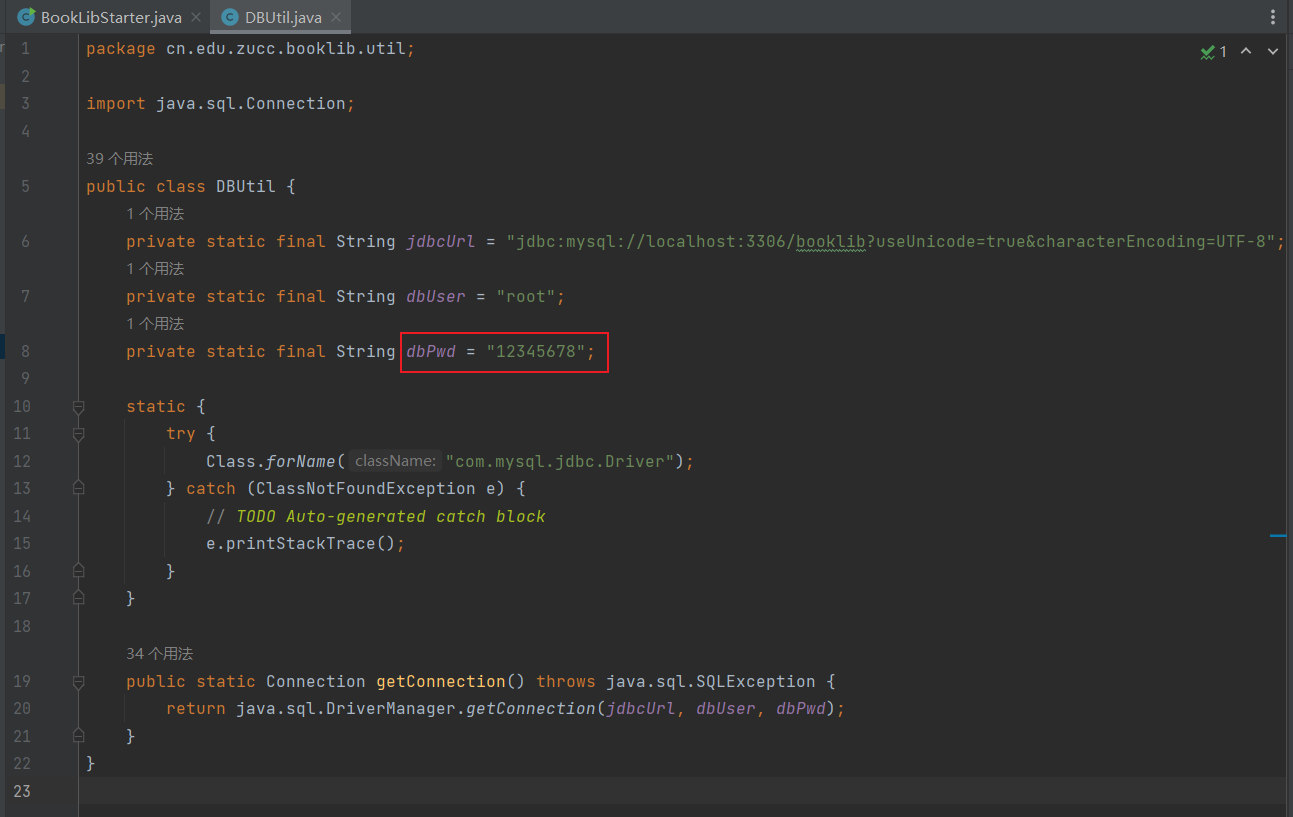
3、在Eclipse中建立并运行图书管理系统工程:参考讲义中的过程
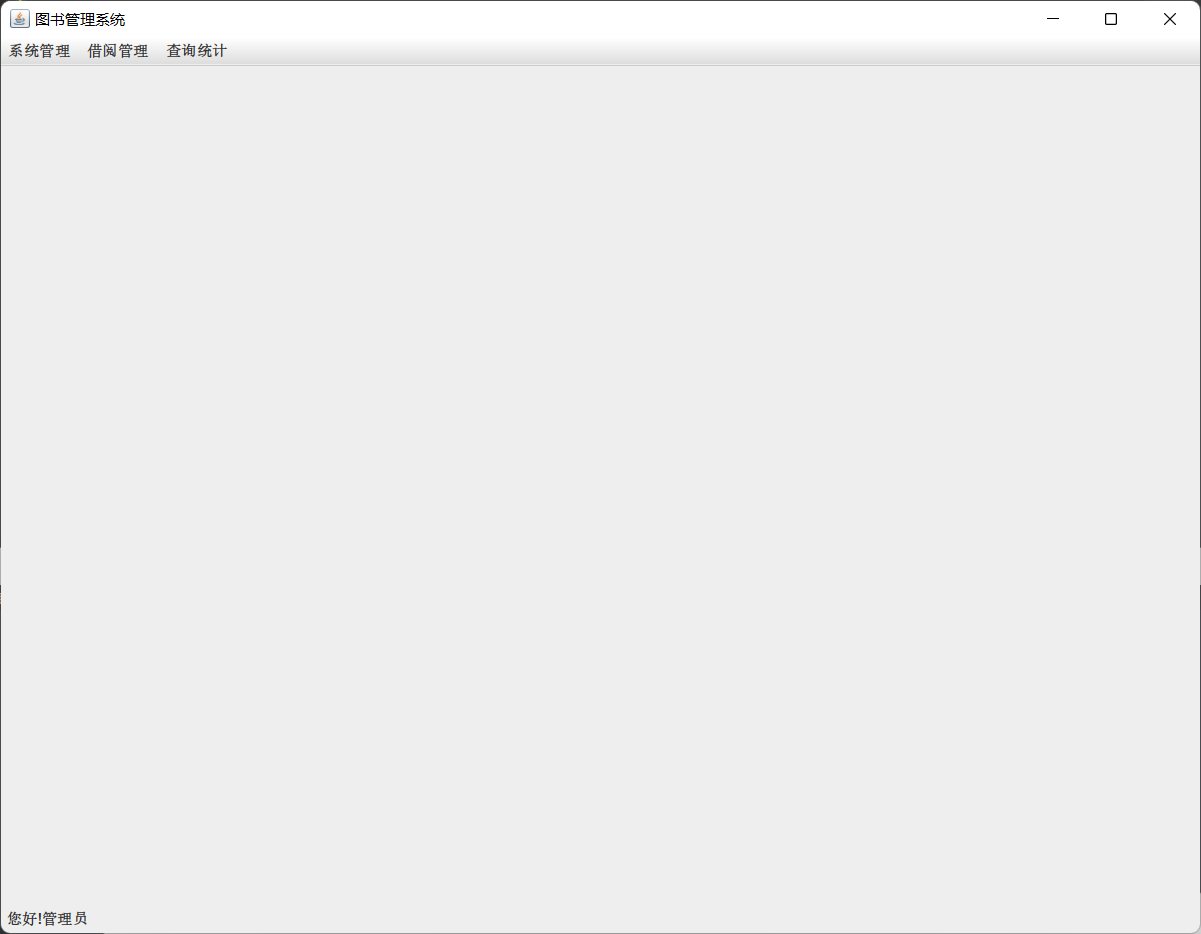
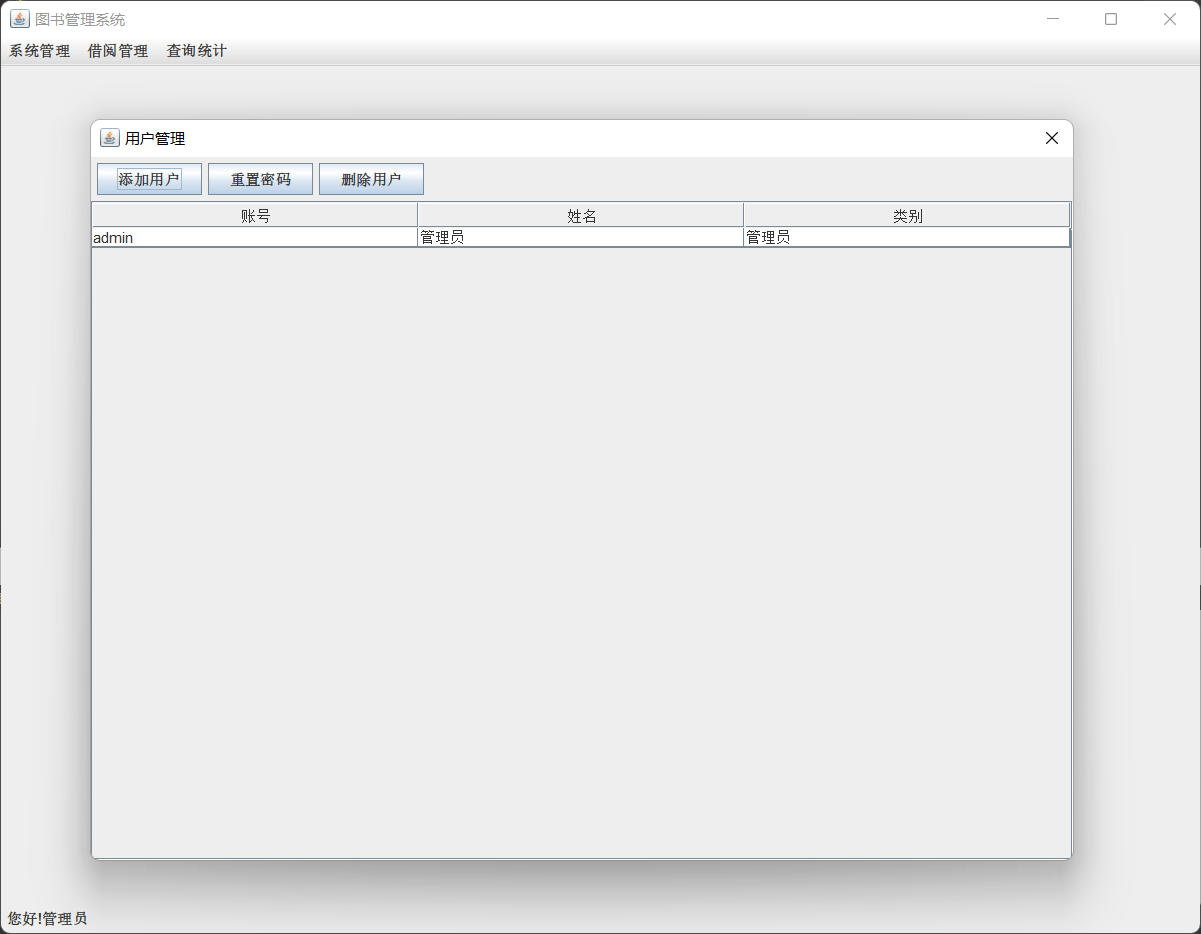
A、用管理员账号登陆后的界面

4、程序分析
A、分析用户管理模块,描述用户添加、重置密码、删除过程涉及的java类、数据库表,并说明实现该功能的流程(说明哪个类实现什么功能、数据库表发生什么变化)
用户添加
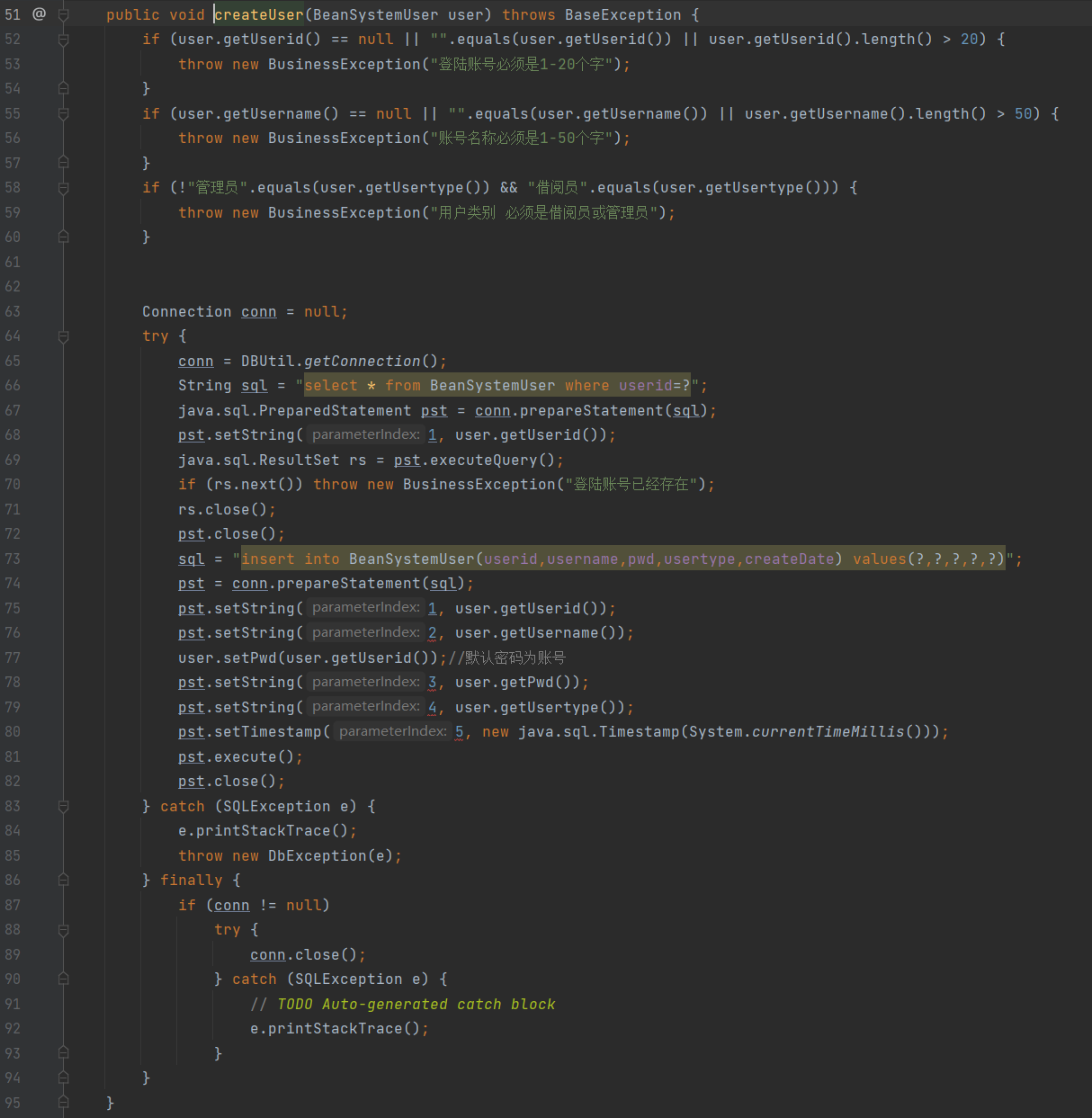
- 主要涉及Java类:
BaseException.javaDBUtil.javaBeanSystemUser.java
- 涉及数据库:
BeanSystemUser
- 流程
- 首先调用了
BeanSystemUser.java类创建了user用户对象来读取输入的创建用户的基本信息,判断输入的信息格式等是否正确,如果有误抛出BaseException.java类定义错误。正确之后调用DBUtil.java类来连接数据库,执行 sql 语句通过查询userid确认是否存在相同用户,确认无相同用户后执行 sql 语句向BeanSystemUser数据库插入数据创建用户
- 首先调用了
重置密码
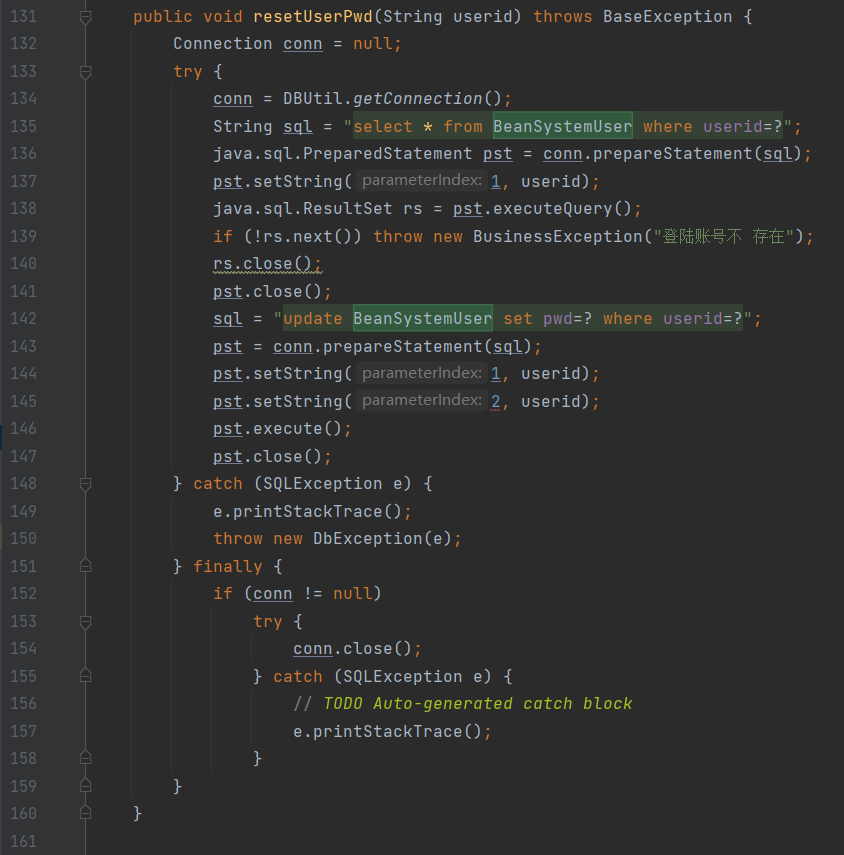
- 主要涉及Java类:
BaseException.javaDBUtil.java
- 涉及数据库:
BeanSystemUser
- 流程
- 首先调用了
DBUtil.java类来连接数据库,执行 sql 语句通过查询userid确认是否存在用户,确认用户存在后执行sql语句更新BeanSystemUser数据库数据修改密码
- 首先调用了
删除用户
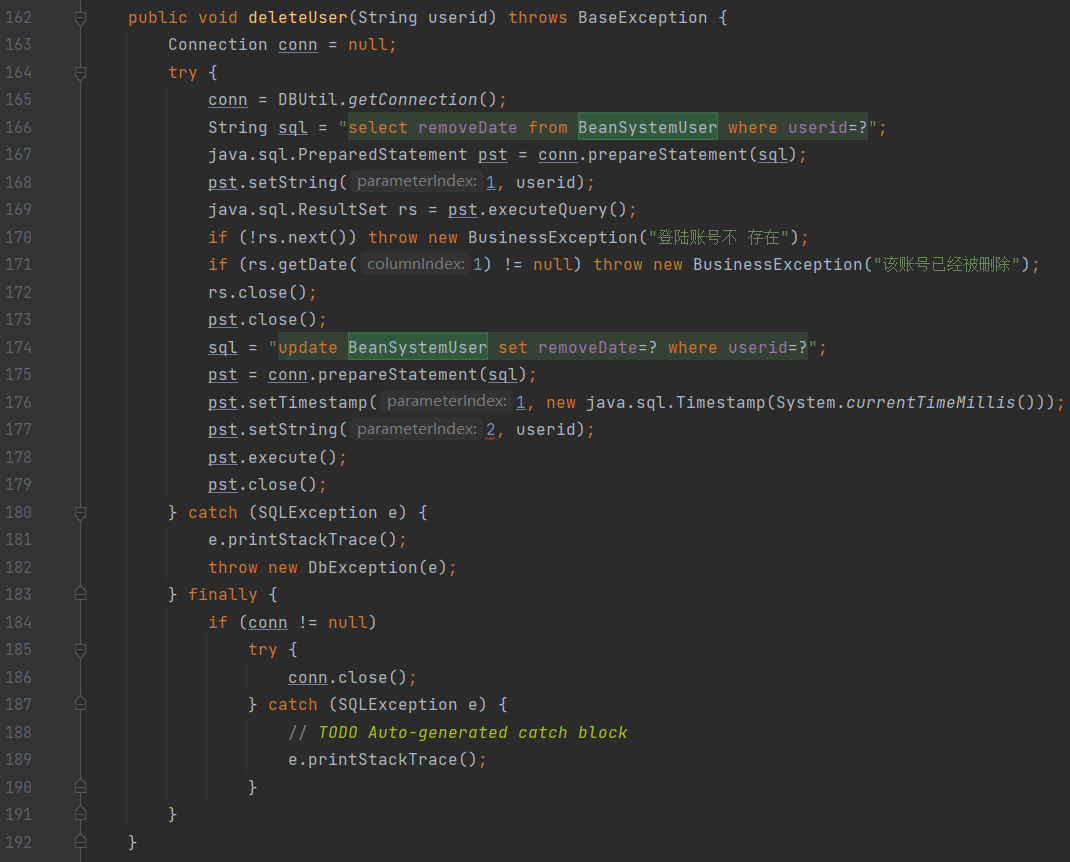
- 主要涉及Java类:
BaseException.javaDBUtil.java
- 涉及数据库:
BeanSystemUser
- 流程
- 首先调用了
DBUtil.java类来连接数据库,执行 sql 语句通过查询removeDate确认是否存在用户和用户是否已删除(如果存在removeDate字段且为空则为用户存在且未删除,如果存在字段不为空则说明已经删除,如果不存在字段则认为是不存在用户),确认用户存在并且未删除后后执行 sql 语句更新BeanSystemUser数据库数据删除用户
- 首先调用了
B、分析读者管理模块,描述读者查询过程涉及的java类、数据库表,并说明实现该功能的流程(说明哪个类实现什么功能)
精确查询
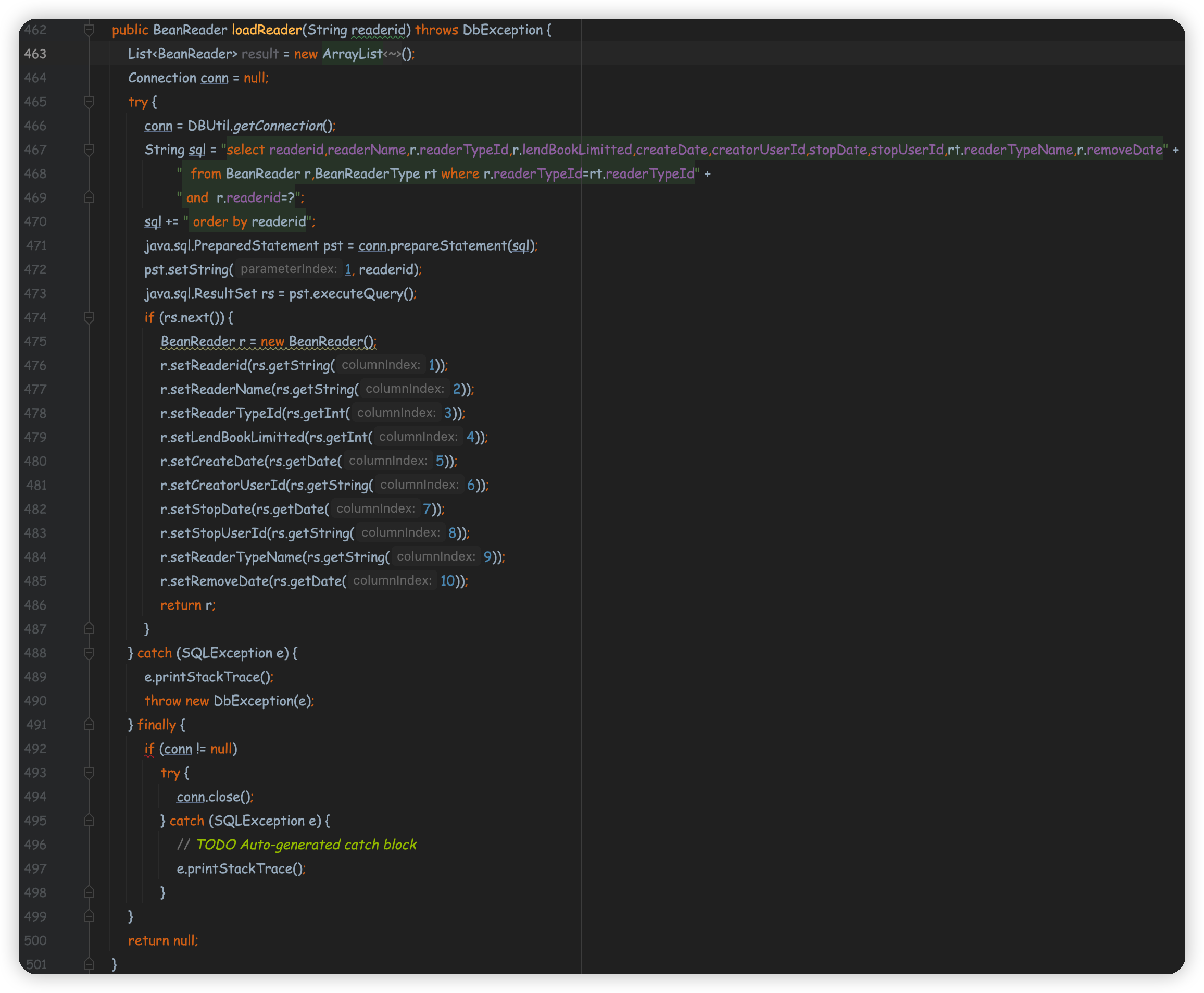
- 主要涉及Java类:
BeanReader.javaDBUtil.java
- 涉及数据库:
BeanReaderBeanReaderType
- 流程
- 首先调用了
DBUtil.java类来连接数据库,根据输入的readerid执行sql语句查询数据,查询到之后再新建BeanReader.java对象将值保存到新对象中,然后返回包含该对象的结果
- 首先调用了
模糊查询
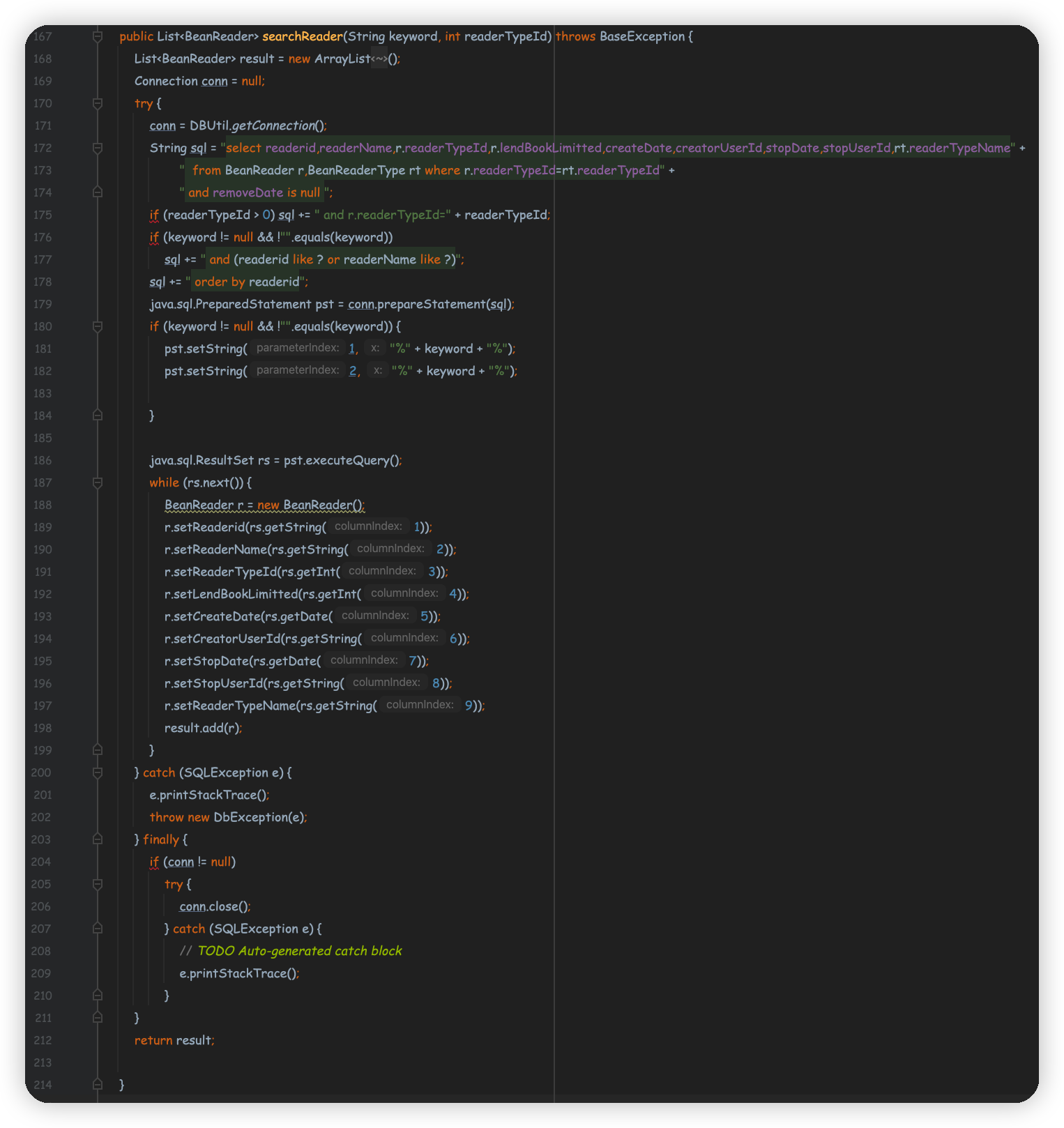
- 主要涉及Java类:
BeanReader.javaDBUtil.java
- 涉及数据库:
BeanReaderBeanReaderType
- 流程
- 首先调用了
DBUtil.java类来连接数据库,如果输入里面的readerTypeId是大于0的整数,就在原查询语句上加入该条件;再判断keyword如果是非空,就把keyword也加入查询语句中。由于无法判断keyword是readerName还是readerid的关键字,所以使用or来添加条件,查询到之后再新建BeanReader.java对象将值保存到新对象中,然后返回包含该对象的结果
- 首先调用了
C、分析图书借阅模块,描述图书借阅流程(说明哪个类实现什么功能、数据库表发生什么变化,说明不能进行图书借阅的几种情况),说明java是如何进行事务管理的
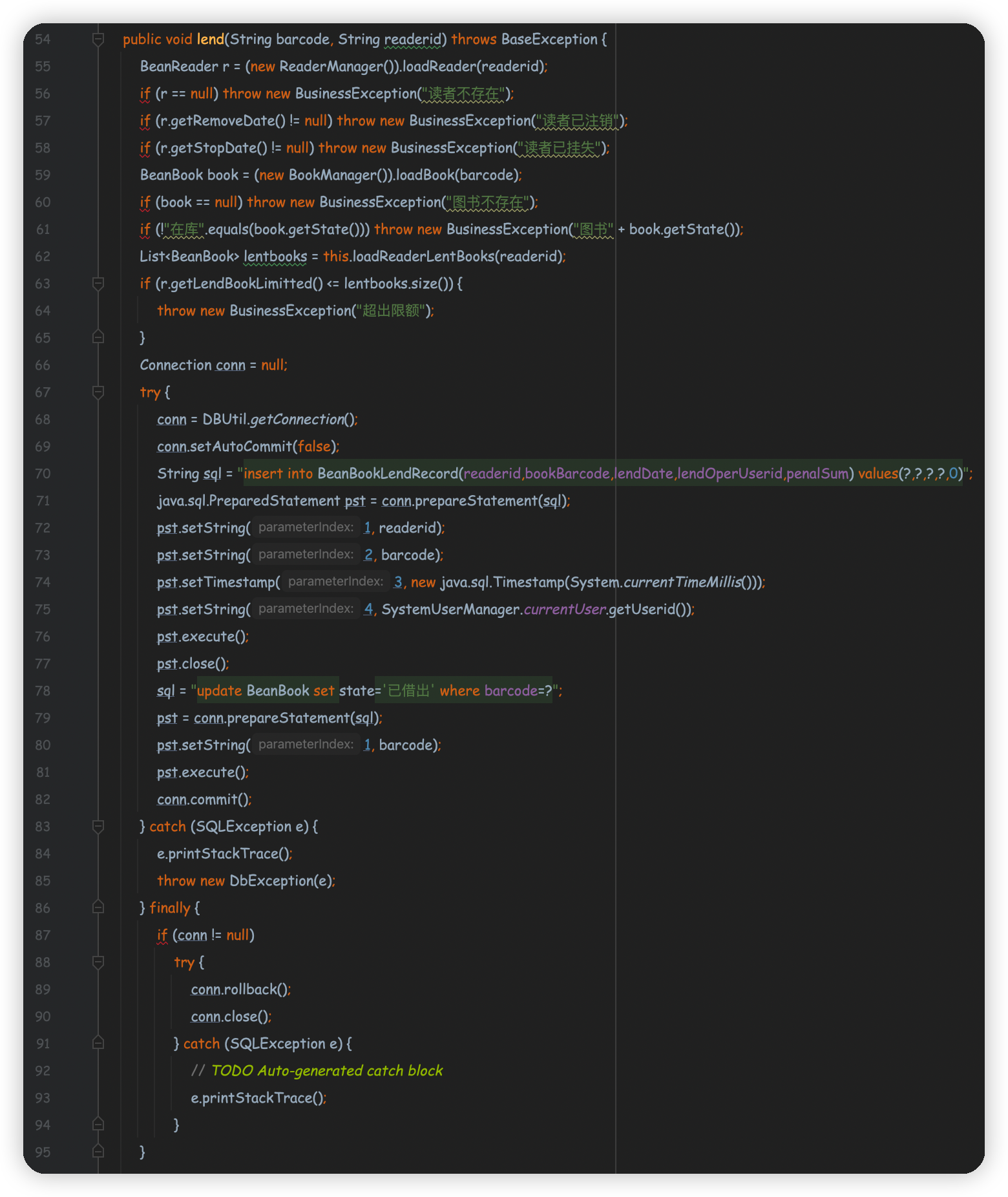
- 主要涉及Java类:
BeanReader.javaReaderManager.javaBookManager.javaDBUtil.javaBeanBook.java
- 涉及数据库:
BeanReaderBeanReaderType
- 流程
- 首先调用了
ReaderManager.java类根据输入的readerid查询了相应的BeanReader对象,在确认对象存在后根据BeanReader的RemoveDate和StopDate判断读者是否注销或挂失。确认没有后再调用BookManager.java类根据输入的barcode查询对应的BeanBook对象,根据该对象的State属性判断是否在库,确认在库之后再调用loadReaderLentBooks来判断BeanReader对象的借书数量是否已达到限额,确认未达到限额后调用DBUtil.java连接数据库执行sql语句插入借书信息数据和更新书本的状态
- 首先调用了
5、利用Statement对象和Result对象实现按出版社名称精确查询出版社功能(精确查询是指查询的目标和查询条件中值完全相同的数据)。
- 第一步:在cn.edu.zucc.booklib.control. PublisherManager类中添加按出版社名称精确查询方法 public BeanPublisher loadPubByName(String name)throws BaseException
- 第二步:编写上述方法,要求当相应名字的出版社不存在时,返回null值;相关代码请参考提取所有出版社函数。
- 第三步:启动booklib主程序,在出版社管理中录入几个出版社
- 第四步:清空cn.edu.zucc.booklib.control.PublisherManager类中的main函数现有内容
- 第五步:在main函数中编写代码,通过调用上面实现的方法按出版社名字查询出版社,如果返回null,则在控制台输出“没有找到出版社”,否则输出出版社编号。(注:控制台输出通过System.out.println(…)函数实现,函数调用的方法参考现有main函数中的内容)。要求main函数中调用两次上述函数,参数分别为一个确实存在的出版社,一个不存在的出版社。
- 第六步:以java application模式运行PublisherManager类,查看输出内容。
A、请给出查询函数的代码。
public BeanPublisher loadPubByName(String name)throws BaseException {
List<BeanPublisher> result = new ArrayList<BeanPublisher>();
Connection conn = null;
try {
conn = DBUtil.getConnection();
String sql = "select pubid,publisherName,address from beanpublisher where publisherName=?";
sql += " order by pubid";
java.sql.PreparedStatement pst = conn.prepareStatement(sql);
pst.setString(1, name);
java.sql.ResultSet rs = pst.executeQuery();
if (rs.next()) {
BeanPublisher r = new BeanPublisher();
r.setPubid(rs.getString(1));
r.setPublisherName(rs.getString(2));
r.setAddress(rs.getString(3));
return r;
}
} catch (SQLException e) {
e.printStackTrace();
throw new DbException(e);
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
return null;
}
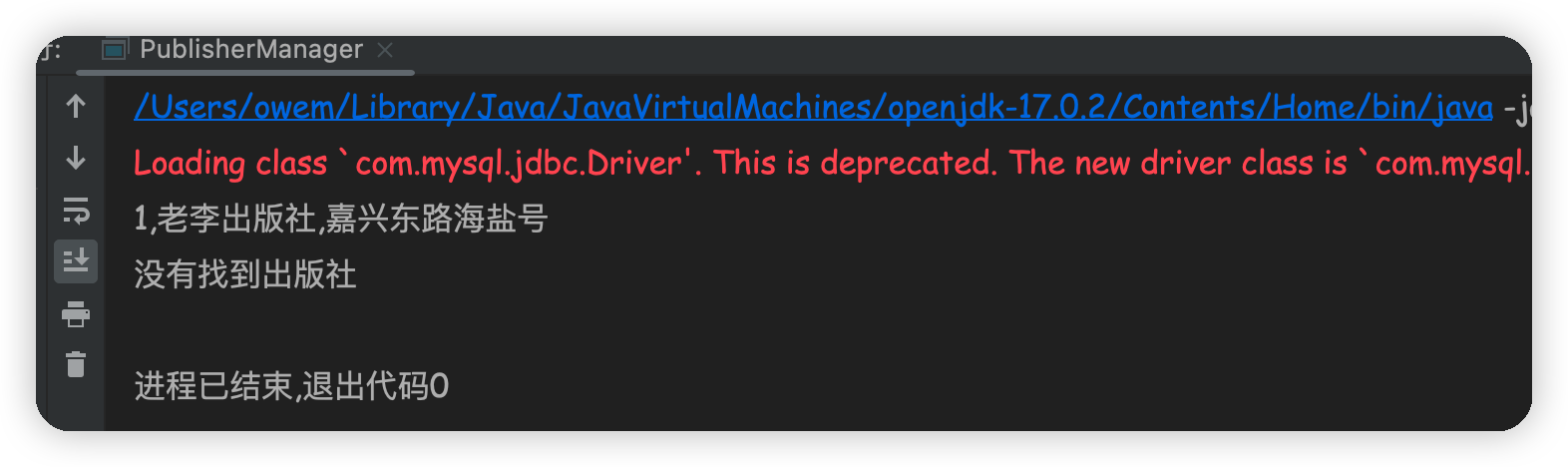
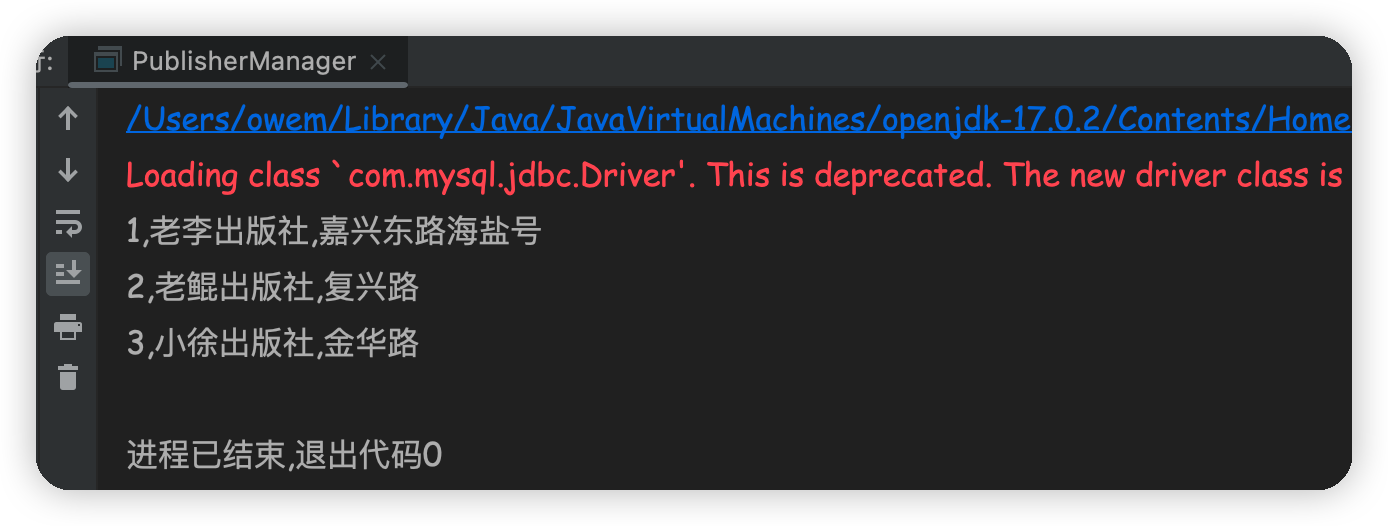
public static void main(String[] args) {
PublisherManager p = new PublisherManager();
try {
BeanPublisher first = p.loadPubByName("老李出版社");
BeanPublisher second = p.loadPubByName("小树出版社");
if(first != null) {
System.out.println(first.getPubid() + "," + first.getPublisherName() + "," + first.getAddress());
} else {
System.out.println("没有找到出版社");
}
if(second != null) {
System.out.println(second.getPubid() + "," + second.getPublisherName() + "," + second.getAddress());
} else {
System.out.println("没有找到出版社");
}
} catch (BaseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
B、说明如何通过JDBC API判断没有查询到指定名字的出版社。
通过boolean java.sql.ResultSet.next() throws SQLException方法获取每次sql语句查询结果,每次调用next()就读入一行数据,当返回false就说明此时指针位于最后一行之后。如果查询后第一次调用next()就返回false,就可以判断没有查询到指定名字的出版社。
6、利用Statement对象和Result对象实现按出版社名称模糊查询出版社功能(模糊查询是指查询的目标包含输入的条件)。
- 第一步:在cn.edu.zucc.booklib.control. PublisherManager类中添加按出版社名称精确查询方法 public List
searchPubsByName(String name)throws BaseException - 第二步:编写上述方法,相关代码请参考提取所有出版社函数。
- 第三步:清空cn.edu.zucc.booklib.control. PublisherManager类中的main函数现有内容
- 第四步:在main函数中编写代码,通过调用上面实现的方法按出版社名字模糊查询出版社,并输出查询到的出版社信息。
- 第六步:以java application模式运行PublisherManager类,查看输出内容。
A、请给出查询函数的代码。
public List<BeanPublisher> searchPubsByName(String name)throws BaseException {
List<BeanPublisher> result = new ArrayList<BeanPublisher>();
Connection conn = null;
try {
conn = DBUtil.getConnection();
String sql = "select pubid,publisherName,address from beanpublisher";
if (name != null && !"".equals(name)) {
sql += " where publisherName like ?";
}
sql += " order by pubid";
java.sql.PreparedStatement pst = conn.prepareStatement(sql);
if (name != null && !"".equals(name)) {
pst.setString(1, "%" + name + "%");
}
java.sql.ResultSet rs = pst.executeQuery();
while (rs.next()) {
BeanPublisher r = new BeanPublisher();
r.setPubid(rs.getString(1));
r.setPublisherName(rs.getString(2));
r.setAddress(rs.getString(3));
result.add(r);
}
} catch (SQLException e) {
e.printStackTrace();
throw new DbException(e);
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
return result;
}
public static void main(String[] args) {
BeanPublisher p;
PublisherManager pm = new PublisherManager();
try {
List<BeanPublisher> lst = pm.searchPubsByName("出版社");
for (BeanPublisher beanPublisher : lst) {
p = beanPublisher;
System.out.println(p.getPubid() + "," + p.getPublisherName() + "," + p.getAddress());
}
} catch (BaseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
B、比较精确查询和模糊查询方法,说明在SQL语句中的主要区别。
主要区别在于where语句后的条件,精确查询使用的符号为=,只有完全等号两边完全相同才能返回true,从而实现精确查询;模糊查询使用的是LIKE谓词和%(代表任意长度),而"%name%"就代表可以匹配全部包含name子串的字符串,从而实现模糊查询。
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Owen

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果